Kaggle study: Freesound General-Purpose Audio Tagging Challenge
- 3 mins오늘 캐글스터디에서 “Freesound General-Purpose Audio Tagging Challenge”란 주제로 발표를 하기로 하여, ppt를 만드는김에 블로그 포스팅 또한 남기려고 한다. 캐글에서 몇주전 “freesound-audio-tagging-2019”란 주제로 새 컴패티션이 열렸는데, 지난 대회인 이 대회에 대한 공부가 조금이나마 도움이 되지 않을까 싶다.
이 포스팅은 주로 디스커션의 Beyond 0.9, sharing my everything so far (updated 24 July)와 여기서 언급하는 커널을 참고하여 정리리하였다. 다른 공개solution도 있지만, 특히 이것을 특정지은 이유는 커널의 형태로 잘 정리되어있고, 모델 향상과정을 잘 설명하고 있기때문이다. 참고로, 이 디스커션과 커널의 작성자인 daisukelab는 최종 private leaderboard에서 14등을 기록하였다.
daisukelab의 Kenrel 내용
daisukelab의 best model이었다고 한다. best solution의 경우 두개의 모델을 더 추가하였다고 언급하였다.
전체 과정
커널의 전체 과정은 다음과 같다.
- 데이터 로딩 및 전처리
- blacklist에 해당하는 샘플 제거
- Cross Validation split & balance # of samples
- train model with data generators
- evaluate with all train sample
###데이터 전처리 전략 오디오 데이터의 길이가 다르기 때문에, 이를 같은 사이즈의 이미지로 표현하기 위해서 두가지 전략을 취하였다.
Approach LH
Sound 시작 부분의 Highest feature resolution을 사용한다. → Motivation : 유용한 정보는 주로 샘플의 앞부분에 등장하는 것으로 보인다. 사운드를 기록하는 방법에 대해 생각해 보면, 이 가정은 타당해 보인다. 또한 LH 방식만으로 모델을 학습하였을 때 보인 좋은 결과가 가정을 뒷받침한다.
Approach X
coarser feature resolution을 감수하고, Sound 를 쪼개서 가능한한 모든 부분을 사용한다. → Motivation : 만약 중요 정보가 중간이나 끝에 나오는 샘플의 경우, Approach LH는 실패할 수 있다. 따라서 전체 샘플 웨이브를 사용하는 방식 또한 필요하다.
최종 solution은 Approach X와 Approach LHㄹ도 전처리된 방식 모두 이용하여 emsemble하였다고 한다.
Blacklist for making clean train dataset
주어지는 학습데이터는 다음의 샘플을 포함한다.
- 수동으로 라벨링된 데이터
- 라벨과 거의 일치해보이는 clean data
- 무음, 낮은 음향 퀄리티, 너무 혼동되거나 라벨과 관련 없어 보이는 데이터
3번 데이터는 모델 성능에 해를 끼친다. 따라서 수동적으로 다음의 과정을 거쳐서 dirty data를 제거한다.
- 현재까지의 best model 선택한다.
- 모델이 예측실패한 샘플의 리스트를 만든다.
- 실패한 샘플을 하나씩 확인하여, 더러운 데이터일 경우 블랙리스트에 추가한다.
- 안 좋은 샘플이 없을 때까지 위 과정을 반복한다.
모델
공개된 커널의 모델은 특별한 점은 없다.VGGNet이나 SEResnet을 기본으로 한다.
data generator
data를 aubmentation하기 위해 generator에서 사용하는 방법이 재밌는데, 두가지 방법을 사용한다. 하나는 mixup: BEYOND EMPIRICAL RISK MINIMIZATION이고, 다른 하나는 random erasing data augmentation이다.
우선 mixup의 코드를 봐보자. 굉장히 간단하고 직관적이다. 
mixup은 Beta distribution을 따르는 lambda값을 기준으로 두 샘플의 combination을 만들어 사용한다. mixup vicinal distribution은 모델이 학습데이터 중간에서 선형적으로 행동하도록 하는 data augmenation의 형태로 이해될 수 있다. 이 논문의 저자는 linear behaviour가 학습 샘플 외의 것을 예측할때 발생하는 바람직하지 못한 진동(oscillations)을 줄일 수 있다고 주장한다. 또한 선형성(linearity)은 Occam’s razor의 관점에서 good inductive bias이다. [^1]
다음 그림은 클래스에서 다른 클래스로 선형적으로 변할때, mixup이 좀더 스무스한 예측을 제공함을 보여준다. 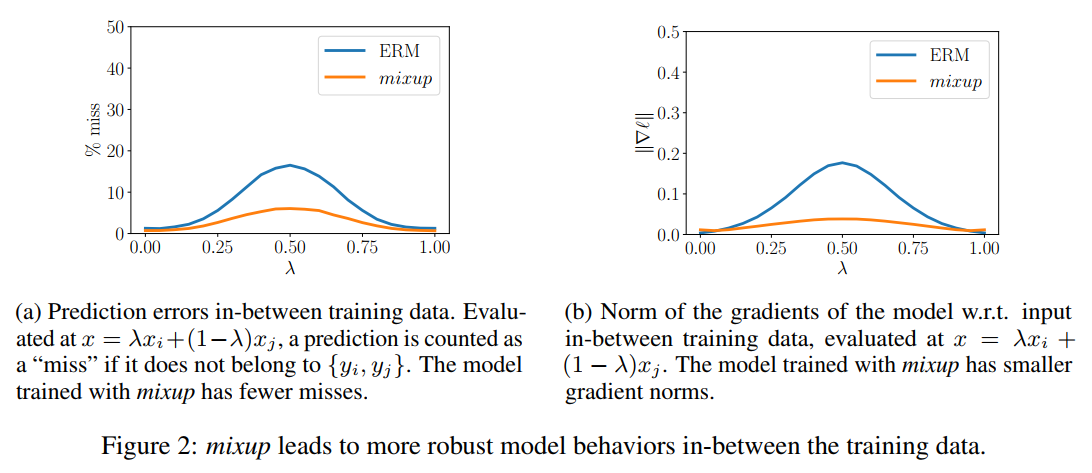
random erasing은 더욱 직관적이고 간단하다. 그림에서 임의의 부분을 지우고 모델에 학습시킨다. 아래 그림을 확인하자. 
또한 커널에서 데이터의 balance를 주기 위하여 오버샘플링도 적용하였다.
From Discussion
위의 커널이 daisukelab의 best solution이었다고 한다. 디스커션의 적힌 내용을 좀더 추가한다.
Updated 24 July
참고로 위의 커널이 8월1일에 업데이트된 부분이며, discussion이 여러번 수정된것으로 보인다.
daisukelab가 여러 실험과 결과를 분석한 내용이다.
- test set은 manually verified 샘플만을 포함하기 때문에 트레인 샘플과 차이가 있다. 즉 모델에 feeding하기전 적합한 샘플을 찾는 것이 중요하다. (블랙리스트를 만든 동기로 보인다.)
- public LB가 manully verified test sample로만 이루어져 data quantity와 quality distribution이 차이가 날 수 있다. 따라서 LB보다 CV를 믿는게 좋다.
- 오디오 전처리는 가능한 많은 정보를 그대로 두는게 좋다.
- 모델은 길이에 큰 상관 없지만 너무 큰 capacity를 주지 말아라.
이 때 [Simple CNN Approach](https://www.kaggle.com/daisukelab/simple-cnn-approach에 SEResNet-50을 베이스로 하여 사용하였다고 한다.
결론
daisukelab의 커널과 discussion을 바탕으로 freesound audio tagging 문제를 어떻게 접근하는지 살펴봤다. 요즘 계속 깨닫는게, 모델에 어떻게 인풋데이터를 좋은 정보로 인코딩하여 보낼지가 성능을 크게 좌우할 수 있다는 것이다. mixup이란 방식도 이번에 알게 됐는데, 굉장히 흥미롭다. ㅎㅎ
Reference
1) Beyond 0.9, sharing my everything so far (updated 24 July)
2) freesound-dataset-kaggle-2018-solution Kernel
[^1]: 오컴의 면도날이란 어떤 사실이나 현상을 설명할 때, 논리적이고 가장 단순할수록 진실에 가깝다는 원칙을 말한다.

Huiwon Yun
아무것도 하지않으면 아무일도 일어나지 않는다.