NLP Pretrained Model : BERT (2)
- 4 mins이전 포스팅에서는 BERT 의 전체적인 구조에 대해서 정리하였다. 이번 포스팅에서는 BERT가 실험한 NLP task에서 fine-tunning을 적용한 방법과 결과를, 그리고 ablation studies까지 정리하여 BERT paper에 대한 정리를 마무리한다.
Experiments
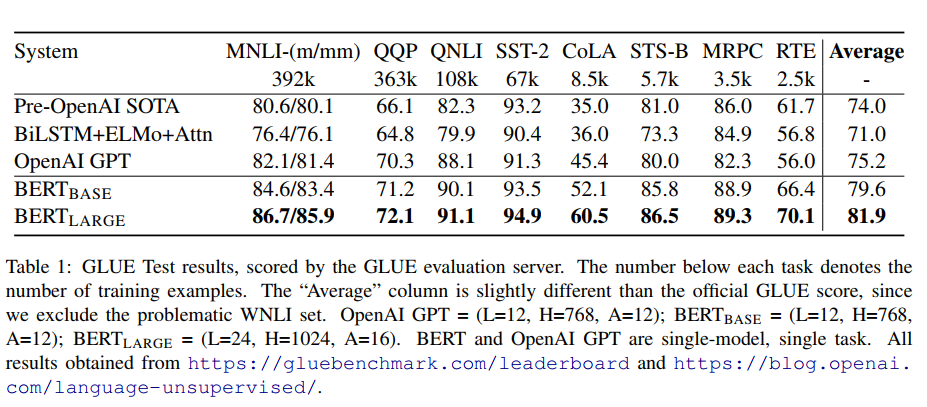
BERT는 GLUE와 squad 를 포함하여 총 11가지 NLP task에 대해서 실험을 하고 결과를 보고하였다.
GLUE Datasets
GLUE(Ganeral Language Understanding Evaluation) benchmark는 말 그대로 다양한 nlu task의 집합체다. GLUE의 대부분의 dataset은 이미 존재하던것이었지만, train, dev, test splits으로 나눠지고, 평가에 일관성이 없음과 test set overfitting 이슈를 완화시키기 위해 evaluation server 를 셋업되었다.
GLUE는 다음의 데이터셋을 포함한다.
- MNLI(Multi-Genre Natural Language Inference): entailment classification task
- QQP(Quora Question Pairs): Quora에 올라온 질문 페어가 의미적으로 동일한지 확인하는 테스크
- QNLI(Question Natural Language Inference): SQuAD의 이진분류 버전. paragraph가 answer를 포함하는지 안하는지 확인하는 문제.
- SST-2(Stanford Sentiment Treebank): 단문장 이진분류문제. 영화리뷰에서 추출된 문장에 감정이 표기되어있음.
- CoLA(Corpus of Linguistic Acceptability): 영어문장이 언어학적으로 acceptable한지 확인하는 이진분류문제
- STS-B(Seemantic Textual Similarity Benchmark): 문장쌍이 얼마나 유사한지 확인하는 문제.
- MRPC(Microsoft Research Paraphrate Corpus): 문장쌍의 유사성 확인하는 문제.
- RTE(Recognizing Textual Entailment): MNLI와 유사하나 데이터가 적음.
- WNLI(Winograd NLI): 자연어 추론 데이터셋이나 현재 채점에 이슈가 있어서 BERT 실험에서는 제외됨.
GLUE Results
GLUE에 fine-tunning하는 방식은 아래의 그림과 같다. 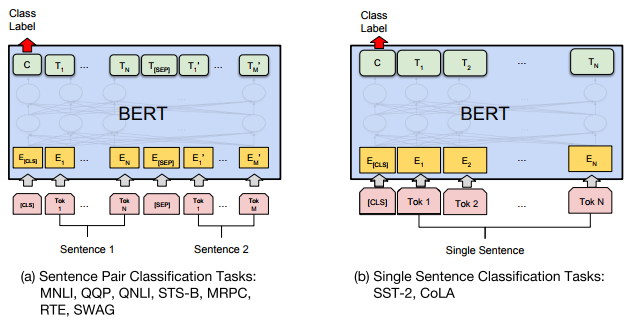 첫번째 input 토큰([CLS])에 해당하는 final hidden vector $C$를 aggregate representation으로 사용한다. 이 $C$에 classification loss를 계산한다. (즉, $log(softmax(CW^T))$)
첫번째 input 토큰([CLS])에 해당하는 final hidden vector $C$를 aggregate representation으로 사용한다. 이 $C$에 classification loss를 계산한다. (즉, $log(softmax(CW^T))$)
BERT_LARGE모델의 경우 small data set에 안정적이지 않아, 여러번 random restart하여 dev set에 가장 성능이 좋은 모델을 선택하였다. (random restart에서 pre-trained model의 같은 checkpoint를 사용하지만, 다른 데이터셋 셔플링과 다른classifier layer 초깃값을 사용한다.) 결과는 아래 표를 참고하자.
SQuAD v1.1
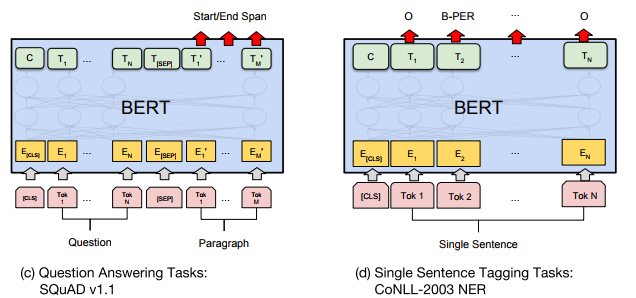
SQuAD는 paragraph와 question pair가 주어지면 정답을 포함하는 text span을 찾는 문제이다. 이러한 span prediction task는 GLUE task와는 다르게 BERT를 적용해야하는데, 저자는 쉽고, 직관적인 방식으로 이를 적응하였다. question과 paragraph를 각각의 single sequence로 보고(즉 각각 A, B embedding으로 구분한다.), 새롭게 학습되는 parameter로 start vector $S$와 end vector $E$를 추가하였다. $i$th input token의 마지막 hidden vector를 $T_i$라 할때, $i$th 토큰이 start일 확률은 softmax를 통해 구해진다. \(P_i = \frac{e^{S·T_i}}{\sum_{j} e^{S·T_j}}\)
answer span의 end도 위와 같은 식으로 구해진다. inference할 때는, end prediction이 start prediction에 조건부적으로 구해지도록 휴리스틱한 방법이 추가되었다. 한편, 데이터를 보강하는 방법을 사용하여(triviaQA data추가), 더 성능을 높였다. SQuAD의 결과는 아래와 같다. (참고로 현재 스코어보드의 상위권 모델들은 모두 BERT를 이용한것이다.) 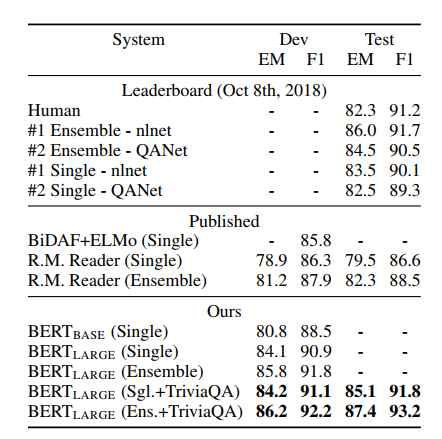
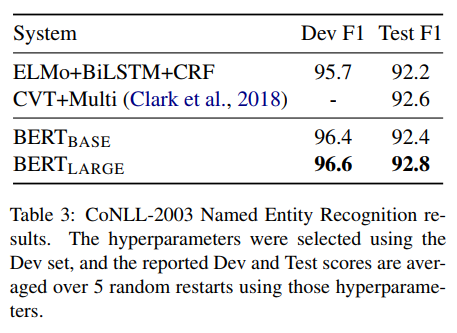
Named Entity Recongnition
token tagging task에서의 BERT의 성능을 평가하기 위해 CoNLL2003 NER dataset에 BERT를 파인튜닝하였다. final hidden representation $T_i$는 NER label set에 대한 classification layer를 통과한다. (에측은 주변 예측에 조건부적이지 않다.) WordPiece tokenization을 사용하기 위해 first sub-token에 해당하는 hidden vector를 classification layer에 입력으로 사용한다.다른 task와 달리 NER에선 cased WordPiece를 사용하였다. 결과는 다음 표와 같다. SQuAD와 NER task에 해당하는 모델은 그 아래 그림을 참고하자.
SWAG
SWAG(The Situations With Adversarial Generations)은 video captioning의 sentence가 주어졌을때, 4개의 문장중 연속되는 상황으로 타당할 문장을 고르는 task이다. task-specific parameter로 vector $V$가 추가된다. V와 choice i에 해당하는 final aggregate representation $C_i$의 dot product에 softmax를 적용하여 4개의 선택지에 대한 확률을 구한다.
Ablation Studies
저자는 BERT의 다양한 특면에 대해서 ablation task를 진행하였다.
Effect of Pre-training tasks
BERT가 주장하는 deep bidirectionality의 중요성을 실험하기 위해 다음 두 실험을 진행한다. next sentence predcition(NSP)없이 MLM만을 실험한 모델과 LTR(Left-To-Right) 모델에 no NSP로 실험하는 경우이다. LTR 인 경우 masking없이 모든 단어를 예측한다. LTR 시스템을 강화시키기 위해 fine-tunning에서 top layer에 biLSTM을 추가시켰다.
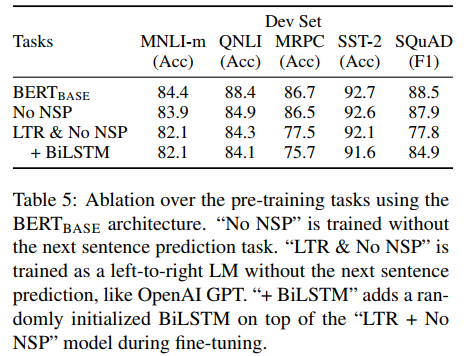
위 표에서 보듯이 SQuAD에선 deep bidirectionality의 중요성이 확연하다. MRPC의 낮은 성능은 테스크 특성인지, 적은 data 사이즈 때문인지 불분명하다.
ELMo가 그런것처럼 LTR과 RTL을 분리해서 삭습시키고 concat하는 방식도 가능하지만, 이러한 방식은 single bidirectional model의 두배의 비용이 들고, QA같은 task에서는 직관적이지 않으며 deep bidireciontal model보다 파워풀하지 않다.
Effect of Model size
아래 표에서 처럼 large model이 상당한 정확도 향상을 이끌수 있음을 확인할 수 있다. 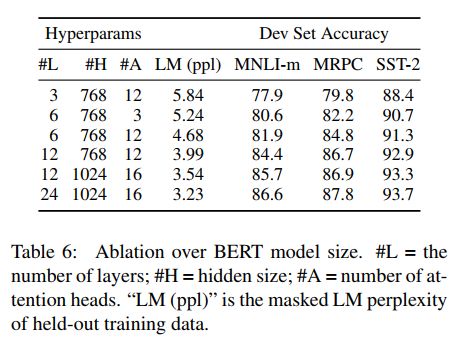
Effect of Number of Training Steps
BERT은 많은 pre-training step이 필요하다. MLM model를 LTR model보다 수렴하는데 느리지만, LTR의 성능을 금새 추월한다. 
Feature-based Approach with BERT
지금까지 서술한 실험들은 fine-tunning approach에 초점이 맞춰져 있었다. 하지만 모든 NLP task가 transformer encoder 구조로 쉽게 나타낼 수 있는 것은 아니며, task-specific한 모델 구조가 필요할 수 있기 때문에 feature-based approach로 pretrained model의 feature를 뽑는 방식이 더 이익인 경우도 있다. 또한 계산량에서도 이익을 얻을 수 있다. CoNLL task에서 BERT를 feature-based approach로 실험한 경우 결과를 비교하면 다음과 같다. 
Conclusion
지금까지 language model에서의 transfer learning을 이용한 실험들로 unsupervised pre-training이 많은 language understanding system의 필수불가결한 요소가 될 것임으로 보였다. 앞으로의 연구는 BERT가 캡쳐하거나 하지 목하는 언어적인 요소에 대한 조사가 될것을 예상한다.

Huiwon Yun
아무것도 하지않으면 아무일도 일어나지 않는다.