NLP Pretrained Model : GPT
- 4 minsBERT의 많은 부분이 GPT에서 motivation을 얻었기 때문에 GPT를 정리할 필요가 있다. 최근에 GPT2가 나왔으나, 이 포스팅에서는 GPT paper인 Improving Language Understanding by Generative Pre-Training의 내용만을 정리한다. 사실 BERT가 masked lm을 사용하고, GPT는 일반적인 lm을 사용한다는 점, 그리고 BERT는 transformer encoder를 GPT는 transformer decoder를 사용한다는 점을 제외하면 정말 유사하다. 다만 LM pretraining 후 fine-tunning방식이 어떻게 등장하였는지에 대해 GPT에서 자세히 설명하고 있으므로 꼭 읽어볼만 하다.
Improving Language Understanding by Generative Pre-Training
Abstract
레이블링되지않은 text corpora는 충분하지만, 특정 task를 학습하기 위한 레이블링된 데이터는 부족한 실정이다. 저자는 이 페이퍼에서 다양하고 많은 언레이블링 텍스트에 대한 language model의 generative pre-training을 진행한 후, 특정 task에 대해 fine-tunning하는 것이 효과가 있음을 보인다. 이전의 접근방식들과는 다르게, 모델 구조의 작은 수정만으로 효과적인 트랜스퍼를 수행한다. GPT는 12개의 task 중 9개에서 SOTA를 찍어 그 우수성을 입증하였다.
Introduction
레이블링된 데이터셋의 부족과, 설령 레이블링 데이터셋이 충분하더라도, 레이블링되지 않은 데이터로 더 나은 성능 향상을 이룰 것이 기대되지 때문에 이를 활용할 필요성이 대두되어 왔다.
라벨링되지 않은 텍스트로 단어 레벨 이상의 정보를 활용하는 것은 두가지 이유로 챌렌징하다. 첫째, 트랜스퍼하기에 적합한 text representation을 효과적으로 학습하기에 어떤 optimization objective가 효과적인지 불분명하다는 것이다. 최근에 language model, machine translation, discourse coherence같은 다양한 objective가 연구되어왔다. 둘째, 이렇나 학습된 representation이 target task로 트랜스퍼하기에 효과적인 방법에 대한 의견일치가 되지 않았다. 그래서 모델 아키텍처를 테스크에 맞게 수정하거나, 복잡한 learning scheme을 거치거나, 추가적인 learning objective를 더하는 방법들이 존재하였다. 이러한 불확실성은 semi-supervised learning을 어렵게 한다.
이 논문에서는 unsupervised pre-training과 supervised fine-tuning을 결합하여 language understanding task에 대한 semi-supervied approach를 탐구한다. 여기서 목적은 다양한 테스크에 적용가능한 universal representation을 학습하는 것이다.
저자는 two-stage 학습 과정을 적용한다. 먼저 레이블되지 않은 데이터로 language model objective로 network를 학습시킨다. 이어서 target task를 위한 supervised objective로 파라미터를 파인튜닝한다. 모델 구조로 다양한 nlp task에서 우수한 성능을 보인 transformer을 사용한다.
Related work
Semi-supervised learning for NLP
초기에는 단어 레벨이나 phrase 레벨의 통계를 계산하기 위해 unlabled data를 활용하였고, 이 값이 supervised model의 feature로 사용되었다. 지난 몇년 간, unlabled corpora로 학습시킨 word embedding을 활용하여, 다양한 task의 성능을 향상시켰다. 그러나 이러한 접근방식은 word level의 정보를 주로 전달하기에 좀 더 higher-level의 의미를 전달하는 것을 목표로 하게 되었다. 최근 방식은 phrase-level이나 sentence-level embedding을 적용하는 방식이 연구되어 왔다.
Unsupervised pre-training
Unsupervised pre-training의 목적은 좋은 initialization point를 찾는 것이다. 최근 연구는 image classification, speech recognition, entity disambiguation, MT와 같은 다양한 테스크에서 이 방식이 사용될 수 있음을 보여줬다. GPT의 연구와 가장 유사한 라인의 연구는 ULMFit와 Semi-supervised sequence labeling이다. 그러나 LSTM model의 사용은 prediction능력을 short range로 제한한다. 반면에 transformer구조는 더 긴 길이의 언어적인 구조를 캡쳐할 수 있음을 실험을 통해 보였다. 또한 GPT는 transfer할 때 아주 작은 모델구조 변화만을 필요로 한다.
Auxiliary training objectives
보조적인 비지도 학습 목적함수를 추가하는것 또한 준지도학습의 선택가능한 형태 중 하나다. 저자도 또한 auxiliary objective를 사용하여 실험해 봤지만, unsupervised pre-training이 이미 타겟 테스크에 연관있는 언어적인 면을 상당히 학습했음을 보인다.
Framework
두 단계 학습 과정을 거치며, 첫번째 단계에서 high-capacity language model을 학습하고, 이어서 특정 task에 대하여 라벨링된 데이터로 fine-tunning 단계를 진행한다.
Unsupervised pre-training
코퍼스 $\mathcal{U}=${$u_1, …, u_n$}가 주어지면, 다음의 likelihood를 최대화하는 standard language modeling objective를 사용한다.
이 때 k는 context window의 크기이고, $\Theta$는 NN의 parameters이다. LM에서는 multi-layer Transformer decoder의 변형을 사용하였다.
$U=(u_{-k},…u_{-1})$는 token의 context vector, $n$은 layer 수, $W_e$는 toekn embedding matrix, $W_p$는 position embedding matrix일 때, 다음의 구조를 가진다.
Supervised fine-tunning
LM objective에 대하여 모델을 pretraining한 후, labeld dataset $\mathcal{C}$를 가지는 target task에 대해 parameter를 조정한다. input tokens $x^1,…,x^m$에 해당하는 label y를 예측해야 때, 위 모델의 마지막 트랜스포머 블록의 activation $h_l^m$을 input으로 하는 linear layer를 추가한다.
즉 다음의 objective가 최대가 되도록 학습한다.
추가적으로 fine-tunning에 auxiliary objective로 LM을 포험하는 것이, supervised model의 generalization을 향상시키고, 모델이 빠르게 수렴하도록하여 학습에 도움이 됨을 확인하였다. 즉 다음의 objective를 최적화한다.
Task-specific input transformations
각 테스크에 해당하는 입력의 변형은 아래 그림으로 직관적으로 확인할 수 있다.
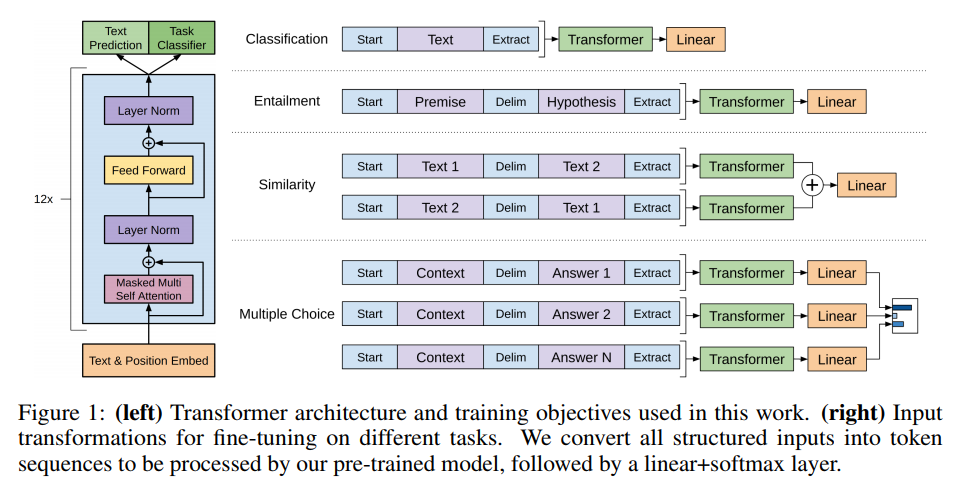
Experiments
Setup
pretrainig데이터로 BookCorpus dataset을 사용하였다.(이 데이터셋은 지금은 원본을 구하기 힘들다.ㅠㅠ 직접 크롤링해야한다.) model에서 눈여겨 볼만한 점은 BPE(byte pair encoding)을 사용하였고, activation으로 GELU(Gaussian Error Linear Unit)를 사용한다. raw text를 클린할때 fifty library를 이용하였고, 일부 구두점이나 스페이스를 표준화하고, spacy toeknizer를 사용하였다.
Supervised fine-tunning
실험에 사용한 데이터셋과 결과는 다음과 같다.
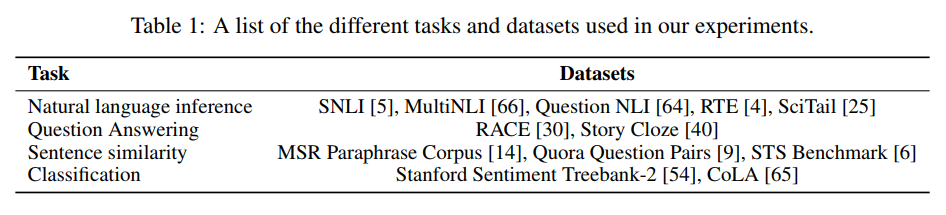
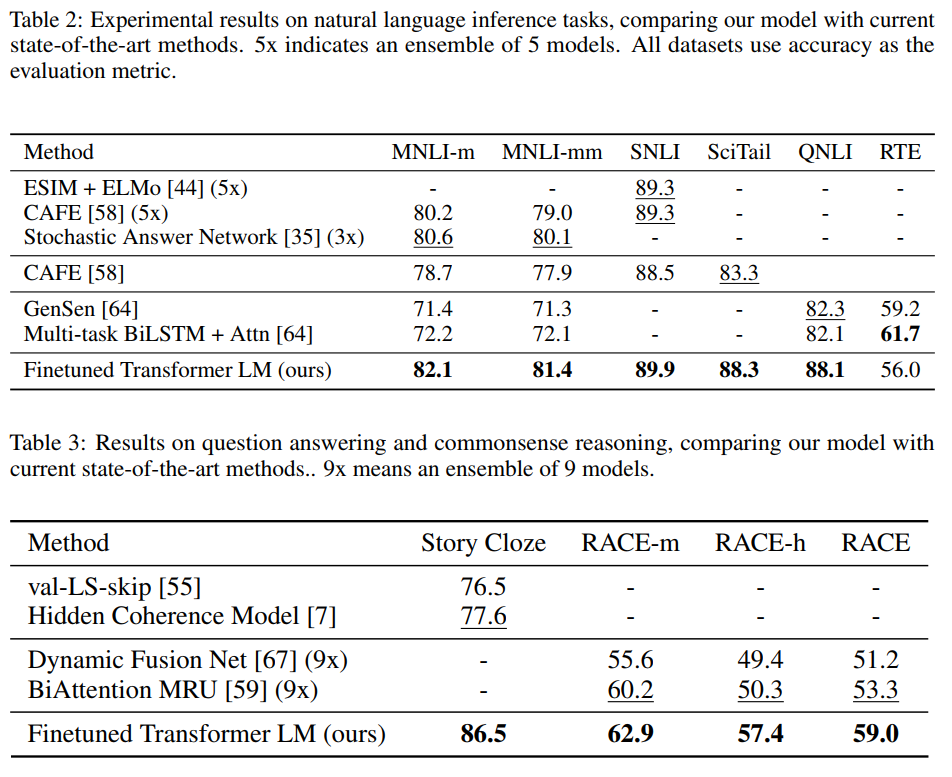
Analysis
Impact of number of layers transfered
pre-trained model의 각 레이어는 target task를 풀기위한 유용한 정보를 포함한다.
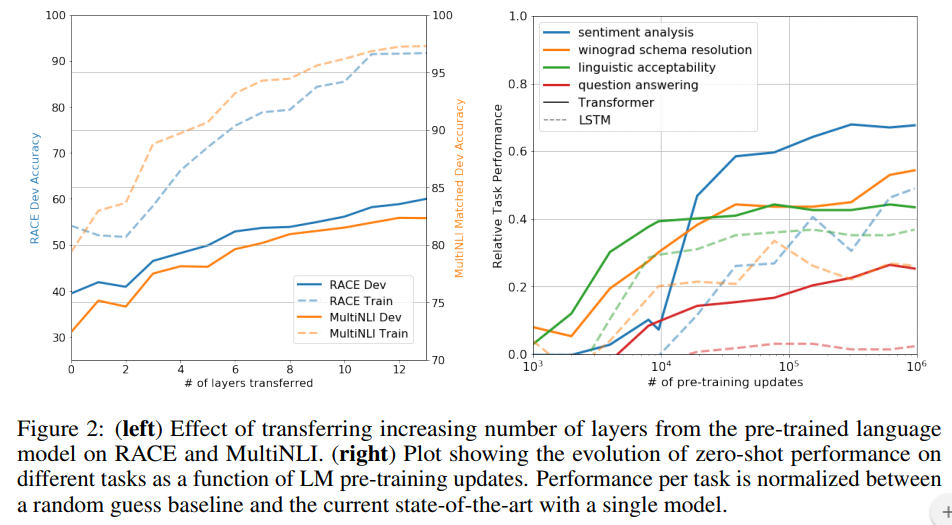
Zero-shot Behaviors
저자는 근본적인 generative model이 LM capability를 향상시키기 위해 많은 task를 수행하는 법을 배울 수 있고, LSTM과 비교해서 transformer의 attentional memory가 transfer에 도움이 된다고 가정하였다. figure2의 오른쪽 그림에서 확인할 수 있듯이 LSTM은 higher variance를 보이는 반면 Transformer구조의 inductive bias는 transfer에 도움이 된다.
Ablation studies
ablation studies로 auxiliary LM objective와 transformer의 효과를 확인할 수 있다. 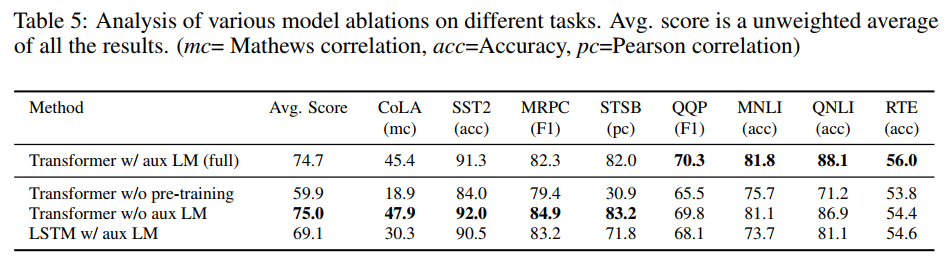
Conclusion
저자는 generative pre-training과 discriminative fine-tunning을 통해 task-agnostic model로 강력한 natural language understanding을 성취할 수 있음을 보였다. 길고 연속된 텍스트로 이루어진 다양한 코퍼스로 pre-training함으로써, 모델이 상당한 world knowledge와 long-range dependencies를 처리할 능력을 가질 수 있음을 보인다. 이 능력을 바탕으로 모델이 개개의 테스크를 풀 수 있도록 성공적으로 해결할 수 있음을 확인하였다.

Huiwon Yun
아무것도 하지않으면 아무일도 일어나지 않는다.