Transformer: Attention is All You Need 리뷰
- 4 minsNLP 모델에서 자주 등장하는 transformer에 대해 정리해본다. 이 논문은 NIPS 2017에 등장하여 MT task에서 SOTA를 찍었고, (한때 QA task인 SQuAD에서 SOTA였던) QANet에서 사용되었으며, 현재 best NLP model이라고 주목받는 BERT의 모듈로도 사용되었다.
Abstract
기존 번역 모델들은 복잡한 RNN, CNN기반의 인코더-디코더 구조를 가졌다. 가장 성능이 좋은 모델은 attention mechanism으로 인코더 디코더를 연결하는 구조였따. transformer는 CNN, RNN 모듈을 완전히 없애고, 오직 attention mechanism을 기반으로 한다. 실험적으로 transformer는 두 MT task(WMT2014 english-to-german, english-to-franch)에서 우수한 성능을 보였으며 다른 task에서도 보편적으로 좋은 성능을 보였다.
Introduction
그동안 RNN 모델은 sequence modeling, tranlation 문제에서 SOTA를 이루었다. machine translation 연구도 recurrent language model과 encoder-decoder구조의 바운더리에서 계속 되었다. 이러한 모델은 이전 hidden state $h_{t-1}$를 고려하여 $h_t$가 결정되고, 본질적으로 병렬 연산을 불가능하게 한다. 최근 연구들에서 factorization tricks나 conditional computation을 통해서 어느정도 계산적 효율성을 얻었다. 그러나 sequential computation의 근본적인 제약은 여전히 남아있었다. Attention mechanism은 input, output sequence의 distance의 상관없이 dependency를 모델링하게 함으로써 다양한 시퀀스 task에서 필수불가결한 요소가 되었다. 그러나 기존 attention구조는 rnn과 결합되어 사용되었다. 이 논문에서는 오직 input output의 global dependency를 그리는데 attention mechanism만을 이용하는 transformer architecture를 제안한다.
Background
Sequential computation을 줄이기 위한 목적으로 진행된 연구들로 Extended Neural GPU, ByteNet, ConvS2S가 있는데, 모두 CNN block을 쌓아 hidden representation을 계산한다. 이러한 모델에서 임의의 두 input 또는 output position의 relate signal을 필요로하는 연산의 수는 거리에 따라 증대된다. distant position의 dependecies를 배우기 어렵게 한다.
Self-attention은 intra-attention이라고 하는데, sequence representation을 구하기 위해 single sequence의 다른 position에 관하여 attention mechanism을 수행한다. self-attention은 MRC, summarization, entailment task등 다양한 task에서 사용되어 왔다.
Model architecture
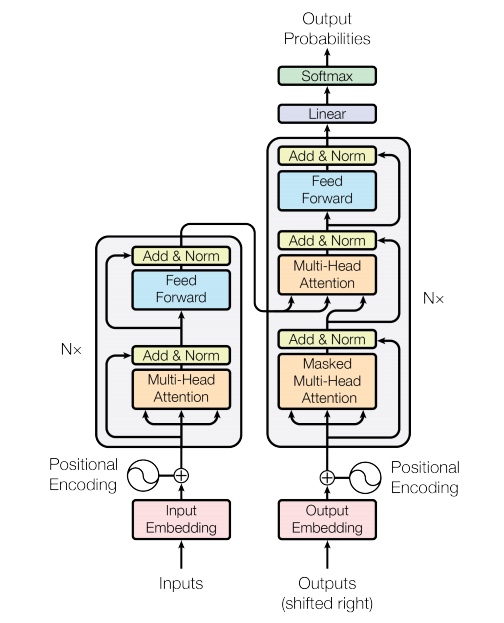
Transformer는 기본적인 encoder-decoder구조를 따르면서 self-attention과 point-wise FC Layer를 sublayer로 가지는 스택구조를 encoder와 decoder 모두에서 사용한다.
Encoder and Decoder Stacks
Encoder : N=6개의 동일한 레이어 구조가 스택되어있다. 각각의 레이어는 multi head attention과 point-wise fc layer로 구성된다. 또한 residual connection과 layer normalization이 적용되었다. residual connection을 수월하게 하기위해 $d_{model}=512$로 고정하였다. Decoder : Encoder와 같이 N=6개의 동일한 레이어가 스택된 구조지만, encoder stack의 output에 multi-head attention을 수행하는 sub-layer가 추가된다. 또한 decoder stack의 self-attention에서 subsequent position에 attending하는 것을 막기 위해 masking을 추가한다.
Attention
attention function의 output은 value에 대한 weighted sum으로 구해지는데, 이 weight는 key에 대한 query의 compatibility function을 수행해 얻어진다. 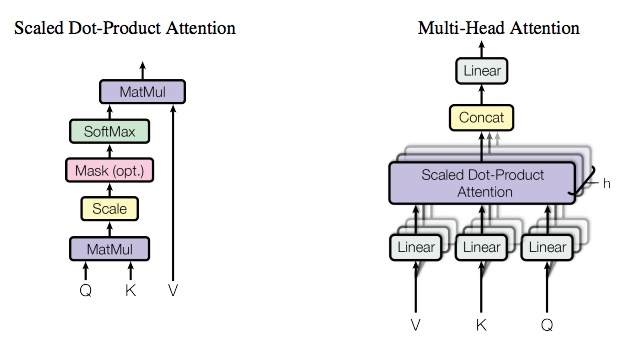
Scaled Dot-Product attention
\(Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\)
주로 사용되는 attention function으로 additive attention과 dot-product attention이 있는데 transformer는 이중 후자에 scaling factor를 추가하여 사용한다. 즉 key와 query의 score function으로 가중치를 구한 후, softmax를 적용하여 normalize한다. 즉 value에 대한 가중치합이 output이 된다. $d_k$(key dimension)가 커질수록 dot product가 커지고, softmax function을 small gradient를 가지는 구간으로 몰아붙이게 된다. 이러한 부작용을 없애기 위해 $\frac{1}{\sqrt{d_k}}$로 scaling한다. 두 attention function은 이론적으로 유사한 complexity를 가지지만, dot-product attention이 실제로 좀 더 빠르고 공간적으로 효율적이다.
Multi-Head attention
저자는 key, value, queries에 대한 single attention을 수행하는 것보다 queries, key, value를 각각 h번 linearly projection한 후 각각 병렬적으로 attention function을 수행하는게 더 효과적인 것을 발견하였다. multi-head attention은 model이 다른 위치의 different representation subspace에서의 정보를 함께 attend하게 해준다. single attention head로는 averaging이 이것을 억제한다. multihead attention을 수식으로 표현하면 다음과 같다. query, key, value의 linear projection dimension은 head 수 h로 나누어지기 때문에 single head attention과 계산비용은 비슷하다. \(MultiHead(Q,K,V) = Concat(head_1, ..., head_h)W^O\)
\(head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)\)
Application of Attention in our model
- encoder-decoder attention: query는 이전 decoder layer에서 오고, memory key와 value는 encoder의 output이다.(즉 key와 value는 동일한 값을 가진다.) 즉 decoder의 모든 위치에서 input sequence의 전체 position에 대해 attend가 가능하다.
- self-attention layer of encoder: self-attention layer에서 query, key, value는 encoder의 이전 layer에서 나온 output이다.
- self-attention layer of decoder: 각 위치에서 각각의 위치까지 attend가 가능하다. 즉 왼쪽 정보만을 보기 위해서 나머지 부분을 $-\infty$로 masking한다.
Point-wise Feed-Forward Networks
attention sublayer를 통과한 후 fully connected feed-forward network를 통과한다. ReLU를 사이에 둔 두 linear transformation으로 구성된다.
\(FFN(x)=max(0,xW_1+b_1)W_2+b_2\)
Embedding and softmax
다른 sequence transduction models와 유사하게, learned embedding을 사용하여 input, output token을 $d_{model}$dimension을 가지는 벡터로 바꾼다. 또한 decoder output을 next-token probability로 바꾸기 위해 usual learned linear transformation and softmax function을 사용한다. 또한 input, output embedding layer에서 같은 weight matrix를 사용한다.
positional encoding
transformer가 rnn이나 cnn을 포함하지 않으므로 문장의 구조를 이용하기 위해 positinal encoding을 embedding에 더해준다. transformer에서는 sine, cosine function이 사용된다.
\(PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})\) \(PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})\)
위 함수가 사용된 이유는 model이 상대적인 position을 쉽게 학습할 것이라고 생각했기 때문이다. learned positional encoding도 실험하여 거의 동일한 결과를 얻었지만, 트레이닝 때보다 긴 문장이 들어왔을때를 대처하기 위해 sinusoidal version을 선택하였다.
Why Self-Attention
한 sequence의 representation을 다른 동일한 길이의 sequence representation으로 mapping시킬때 자주 사용되는 cnn과 rnn layer과 self-attention을 세가지 방면에서 비교한다.  우선 레이어당 총 계산복잡도는 n<d인 경우 self-attention이 더 적은 계산복잡도를 가진다. (그리고 대부분의 task에서 n<d이다.(영어일경우는….ㅠ)) 다음으로 병렬연산을 수행하기 위한 sequential operation의 최소수는 rnn만 O(n)의 복잡도를 가진다. 세번째로 Maximum Path length를 비교했다. long-range dependencies를 학습하는 것은 많은 sequence transduction task에서 중요한 과제였다. 임의의 두 position사이의 최대거리가 짧을수록 long-range dependencies를 학습하기 쉬워진다. self-attention의 경우 O(1)의 복잡도를 가진다.
우선 레이어당 총 계산복잡도는 n<d인 경우 self-attention이 더 적은 계산복잡도를 가진다. (그리고 대부분의 task에서 n<d이다.(영어일경우는….ㅠ)) 다음으로 병렬연산을 수행하기 위한 sequential operation의 최소수는 rnn만 O(n)의 복잡도를 가진다. 세번째로 Maximum Path length를 비교했다. long-range dependencies를 학습하는 것은 많은 sequence transduction task에서 중요한 과제였다. 임의의 두 position사이의 최대거리가 짧을수록 long-range dependencies를 학습하기 쉬워진다. self-attention의 경우 O(1)의 복잡도를 가진다.
Training
- WMT 2014 English-German dataset을 학습시킬 땐 sentence를 byte-pair encoding으로 인코딩하였다. WMT 2015 English-Franch를 학습시킬때는 toekn을 word-piece로 쪼개어서 학습하였따.
- 8 NVIDIA P100 GPU로 base model의 경우 12시간(100K step), large model의 경우 3.5일(300K step)이 걸렸다.
- warmup을 적용한 adam optimizer를 사용하였다.
- dropout, label smoothing의 regularization 기법을 사용하였다.
Results
english-to-german task에서 28.4 BLEU score로 SOTA를 english-to-franch task에서 41.0 BLEU score로 SOTA를 찍었다.

Huiwon Yun
아무것도 하지않으면 아무일도 일어나지 않는다.