Siamese Neural Networks
- 1 minKaggle의 Humpback Whale Identification Competition에서 상위권 커널에서 사용된 샴네트워크에 대해 정리한다. whale data set의 특정 이미지 클래스의 example 수가 매우 적어, 샴 네트워크를 사용한 것으로 보인다. 이 포스팅에서 정리하는 논문은 Gregory Koch의 Siamese Neural Networks for One-shot Image Recognition으로 더 자세한 내용은 원문을 보길 바란다.
Introduction
ML 모델은 보통 많은 양의 데이터를 이용해 학습된다. 그러나 사람의 경우 처음 보는 사물이나 개념도 한번에 빠르게 이해할 수 있다. 이렇게 사람처럼, ML 모델도 single example의 class를 학습하고도, 이를 분류할 수 있을까? 바로 이러한 주제를 다루는 것이 one-shot learning 이다. 샴 네트워크도 one-shot learning에 초점을 맞춘다. (target class의 example을 하나도 보지 않고 맞추는 zero-shot learning과는 구분된다.)
Approach
전반적으로 샴 네트워크로 image representation을 학습하고 이 network의 feature를 one-shot learning에 사용한다. 즉 1)verification tasks(training)에서 같거나 다른 클래스 pair를 식별하도록 모델을 학습시키고, 2)One-shot tasks(test)에서 학습된 feature를 기반으로 class를 예측한다. (아래 논문에서 가져온 그림을 참고할 것.)
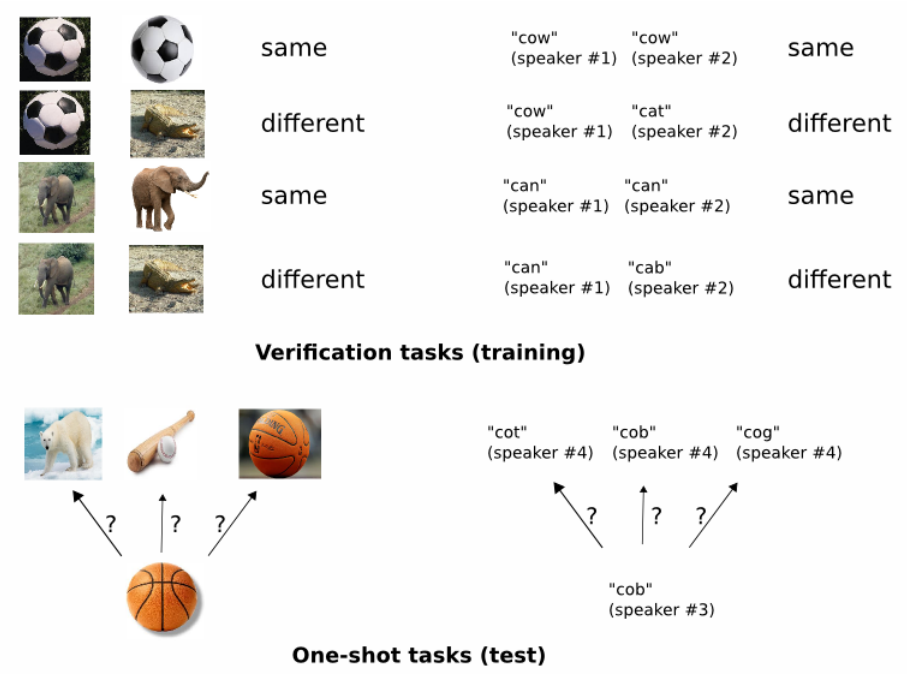
Deep Siamese Networks for Image Verification
샴 네트워크는 1990년 Bromley와 LeCun에 의해 image matching 문제(signature verification)를 해결하기 위한 모델로 처음 소개 되었다. 샴 네트워크는 각각의 입력을 받는 twin network위에 energy function이 결합된 구조이다. 이 function이 각 입력의 high level feature representation사이의 metric을 계산한다.
LeCun이 contrastive energy function을 사용하는데 반해, 이 paper 에서는 두 feature vector $h_1$과 $h_2$의 weighted $L_1$ distance에 sigmoid activation을 결합한 prediction vector에 cross entropy loss를 적용한다.
Model
이 논문에서 사용되는 모델의 구조는 다음 그림과 같다. 모델은 convolutiona layer의 시퀀스로 이루어지며, 마지막 convolution layer 후에 fully-connected layer를 거쳐 siamese twin의 distance metric을 계산한다.
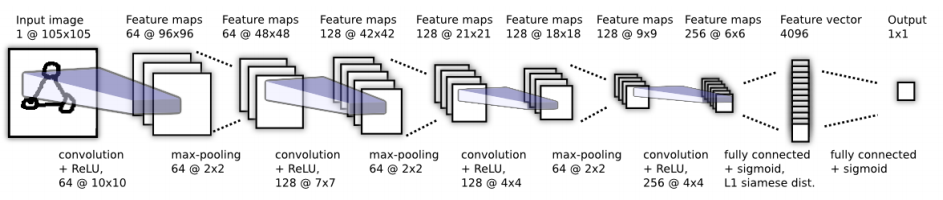
즉 prediction vector $p$는 $\sigma(\sum_j \alpha_j|h_{1,L-1}^{(j)}-h_{2,L-1}^{(j)}|)$ 이다. (즉, input1, 2의 L-1 layer의 vector간 distance이다.) $\alpha_j$는 학습되는 파라미터로 요소간 거리의 중요도에 따라 가중치된다.
Learning
- loss fuction으로 regularized cross entropy를 사용한다. \(\mathcal{L}(x_1^{(i)}, x_2^{(i)})=y(x_1^{(i)}, x_2^{(i)})\log{p(x_1^{(i)}, x_2^{(i)})}+(1-y(x_1^{(i)}, x_2^{(i)}))\log{(1-p(x_1^{(i)}, x_2^{(i)}))} + \lambda^T|w|^2\)
- lr schedule로 1 epoch마다 1%씩 learning rate를 decay한다.
- affine transform으로 data를 augmentation하였다.
Conclusions
Omniglot dataset에서 기존 baseline보다 상당한 향상을 보이므로써 human-level accuracy가 가능함을 보일 뿐만 아니라 다른 도메인의 one-shot learning task로 확장시킬 수 있음을 시사하였다.

Huiwon Yun
아무것도 하지않으면 아무일도 일어나지 않는다.