SpanBert 와 RoBERTa 리뷰
- 8 mins작년 BERT가 발표된 이후로, BERT를 분석하고 성능을 좀 더 향상시키거나 cross lingual model/MTL/특정 테스크에 적용시키는 연구 등 정말 수많은 BERT관련한 논문들이 쏟아졌다. 그 중에서 RoBERTa: A Robustly Optimized BERT Pretraining Approach와 SpanBERT: Improving Pre-training by Representing and Predicting Spans를 소개한다. 이 두 논문이 읽어볼만 한 이유는 다음과 같다. 우선 RoBERTa같은 경우에는 BERT의 어떤 하이퍼파라미터가 성능에 큰 영향을 끼치는지에 대해 실험으로 보여준다. SpanBERT는 새로운 loss function을 제안하고, 이것으로 BERT의 성능을 크게 향상시킬 수 있음을 보여줬다. 따라서 이번 포스팅에서는 이 두 페이퍼를 정리하려고 한다.
RoBERTa
RoBERTa는 Robustly Optimized BERT Pretraining Approach의 약자로 이름 그대로 BERT의 하이퍼파라미터 및 학습 데이터 사이즈 등을 조절함으로써 기존의 BERT의 성능뿐만 아니라 post-BERT의 성능과 버금가거나 훨씬 더 나을 수 있음을 보여준다. 특히 RoBERTa는 이렇게 BERT를 재건함으로써 masked language model만으로도 XLNet과 같은 autoregressive language modeling과도 충분히 겨룰 수 있음을 보여준다. RoBERTa가 BERT와 다른점을 정리하자면 “(1)더 많은 데이터를 사용하여 더 오래, 더 큰 batch로 학습하기 (2) next sentence prediction objective 제거하기 (3)더 긴 sequence로 학습하기 (4) masking을 다이나믹하게 바꾸기”이다.
○ Experimental Setup
Implementation
저자는 FAIRSEQ로 BERT를 재구현하였다. peak learning rate, warmup steps수를 제외하고 BERT의 셋팅을 따랐다. 또한 Adam epsilon값에 학습이 매우 민감하다는걸 발견하였고, $\beta_2=0.98$일 떄 큰 배치 사이즈에서 안정성이 향상됨을 발견하였다. max token수를 512로 고정시켰고, BERT와 다르게 짧은 sequence를 랜덤하게 넣지 않았다.
Data
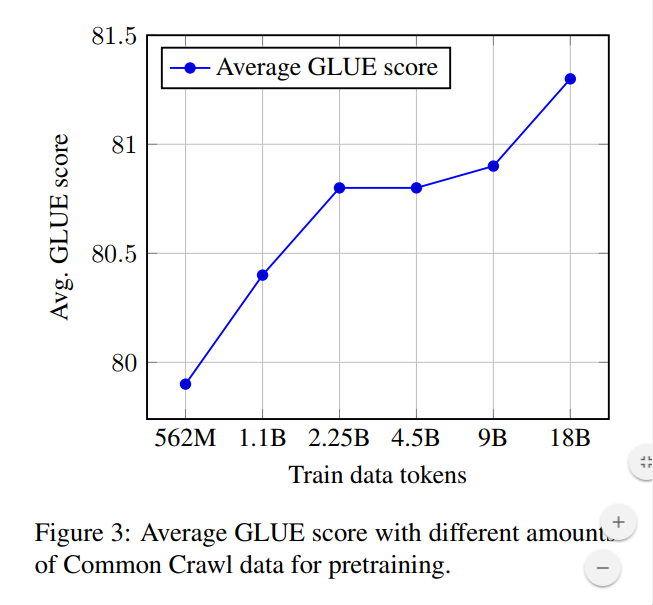
BERT스타일의 pretraining 방식에서 텍스트의 양이 end-task의 성능에 큰 영향을 끼침을 Cloze-driven Pretraining of Self-attention Networks에서 확인하였다. XLNet등의 실험에서 기존 BERT보다 많은 양의 데이터를 모아 학습하였지만, 안타깝게도 이러한 데이터는 공개되지않아 저자는 가능한 많은 데이터를 수집하는데 집중하였고, 160GB에 해당하는 데이터를 모았다고 한다. 데이터의 출처는 BOOKCORPUS(16G) CC_NEWS(76GB), OPENWEBTEXT(38GB), STORIES(31G)라고 밝혔다.
Evaluation
GLUE벤치마크에 대해서 MTL이나 ensemble을 사용하지않고 기존 BERT의 방식을 따라 finetuning하였다. SQuAD v1.1에 대해서는 BERT와 동일한 span prediction방식을 사용했고, v2.0은 추가적으로 questino이 대답할 수 있는문제인지에 대해 이진 분류기를 추가해서 span loss와 classification loss를 결합하여 사용하였다. RACE(ReAding Comprehension from Examination)데이터셋에 대해서도 검증하였는데, RACE는 다른 mrc 데이터셋보다 더 긴 context를 가지고 있고 추론이 필요한 질문의 비율이 높다.
○ Training Procedure Analysis
저자는 BERT base 모델을 베이스로 하여 어떤 선택이 BERT를 튜닝하기에 좋은지에 대해 실험하였다.
Static vs Dynamic masking
오리지널 BERT는 tfrecord를 만드는 전처리 단계에서 마스킹을 하기 때문에 static mask가 적용된 데이터를 학습에 사용하게 된다. 따라서 학습동안 같은 곳에 마스킹된 시퀀스를 보게 된다. pretrain하는 스탭이 늘어날 수록 이는 결정적이게 된다. 따라서 저자는 dynamic masking을 사용하였다. 결과는 BERT와 견줄만하거나 좀 더 우수하였다. 이후 아래 실험들에서도 dynamic masking이 적용되었다.
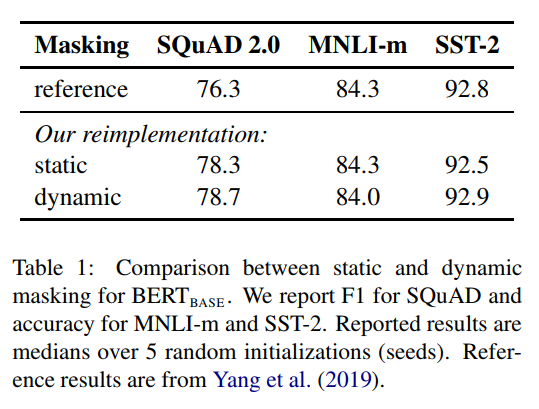
Model Input Format and Next Sentence prediction
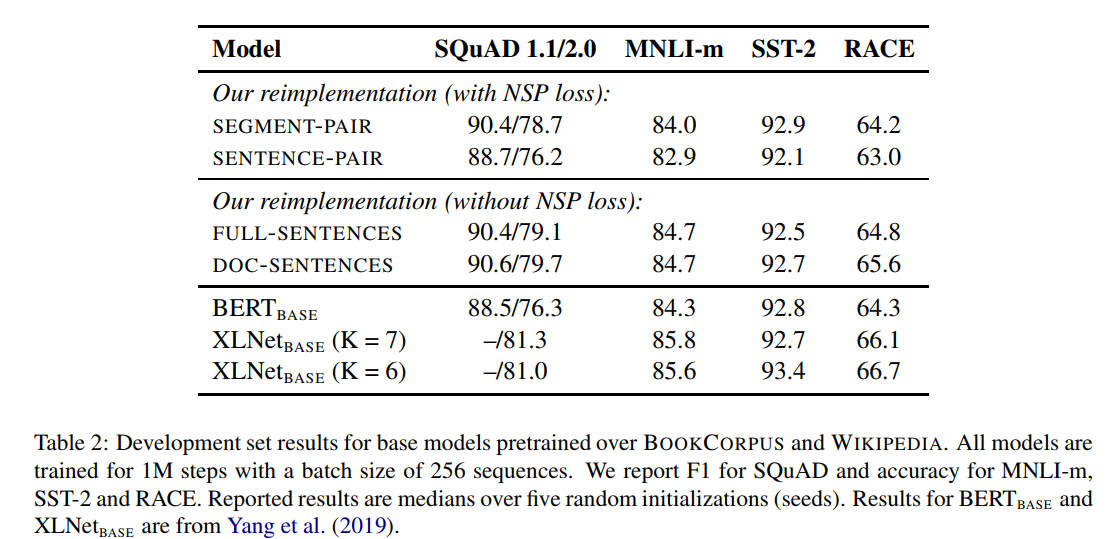
Training with large batches
최근 NMT 연구(Scaling neural machine translation)에서 learning rate가 적절하게 증가된다면 아주 큰 미니 배치사이즈를 사용하는것이 최적화 속도와 end-task의 성능을 높일 수 있음이 확인되었다.
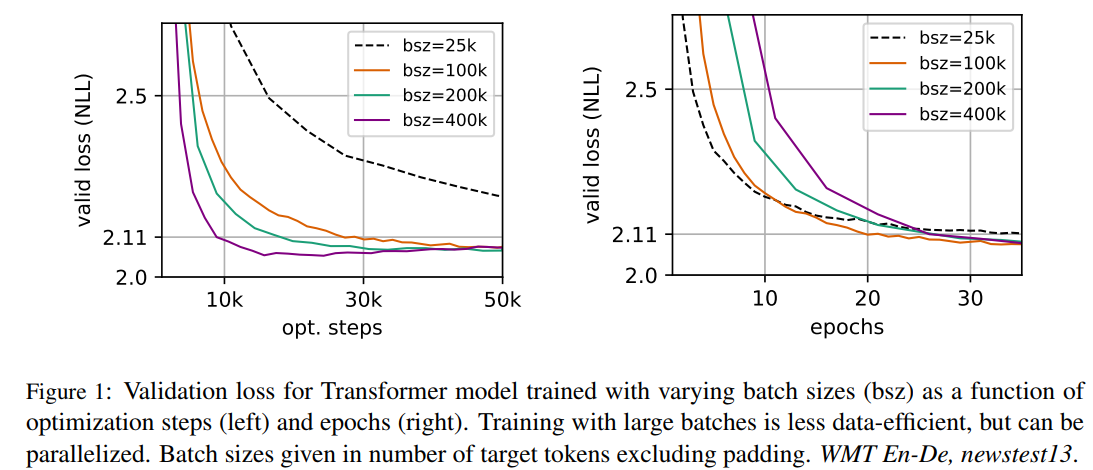
또한 LARGE BATCH OPTIMIZATION FOR DEEP LEARNING: TRAINING BERT IN 76 MINUTE에서는 BERT를 큰 미니배치로 학습할수 있음을 보여주었다. BERT base는 시퀀스 256으로 1M 스탭을 돌았다. 이는 시퀀스 길이2K에 125K step이나 8K길이 배치에 31K step과 동일한 비용이 든다. 여기서 저자는 더 큰 배치로 학습하는 것이 MLM의 perplexity뿐만 아니라 end-task의 성능을 향상시킬 수 있음을 확인하였다.
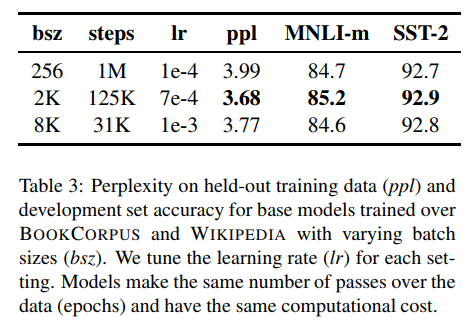
Text Encoding
NLP task에서 BPE를 사용함으로써 보다 큰 사전사이즈를 다룰 수 있게 되었다. 이 사전의 크기는 일반적으로 10K-100K에 달하는데, unicode character는 여기서 상당한 부분을 차지하게된다. Radford는 Language Models are Unsupervised Multitask Learners에서 unicode character 대신에 bytes를 기본 subword unit으로 사용할 수 있음을 제안하였다. 오리지널 버트 구현은 휴리스틱하게 데이터를 전처리한 후에 학습된 30K사이즈의 character-level BPE를 사용하였다. roberta는 Radford의 방식을 따라서 50K 사이즈의 byte-level BPE사전을 사용하였다. 일찍이 실험에서 이러한 인코딩 방식이 몇몇 end-task 성능에서 다소 안 좋은 결과를 보였지만, 저자는 그럼에도 보편적인 인코딩 스킴이 마이너한 성능저하보다 나을 것이라 믿어 나머지 실험들에서 이 인코딩 방식을 사용하였다고 한다.
○ RoBERTa
위 섹션에서 저자는 BERT를 수정하여, end-task에서 더 높은 성능을 보일 수 있는 방법들을 설명하였다. 그리고 이 설정을 RoBERTa(Robustly optimized BERT Approach)라 명명하였다. 다시 정리하자면, dynamic masking, FULL-SENTECES(wo NSP), large mini-baches, larget byte-level BPE를 사용하였다. 또한 추가적으로 이전 연구들에서 덜 강조되었던 pretraining에서 하용되는 데이터와 trainig pass의 수에 대해 실험하였다. XLNet의 경우에는 기존 BERT에 비해 10배 많은 데이터를 사용하고, batch size는 4배로, step은 1/2배였고, 즉 BERT와 비교하면 4배 더 많은 sequence를 보게 된다.
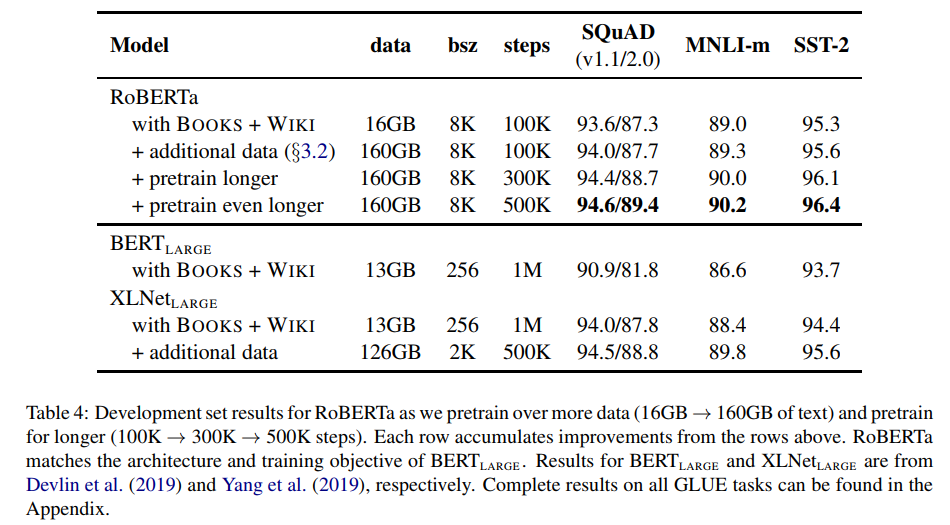
BERT_large와 XLNet과의 비교를 위해서 RoBERTa는 BERT large의 구조를 따라 실험하였다. 위 표에서 처럼 100K, 300K, 500K순으로 pretraining step을 증가시켰고, 데이터의 양도 증가시켰다. 결과적으로 위 표에서 더 많은 데이터와 pretrain step이 end-task에서 성능을 증가시킴을 확인할 수 있다.
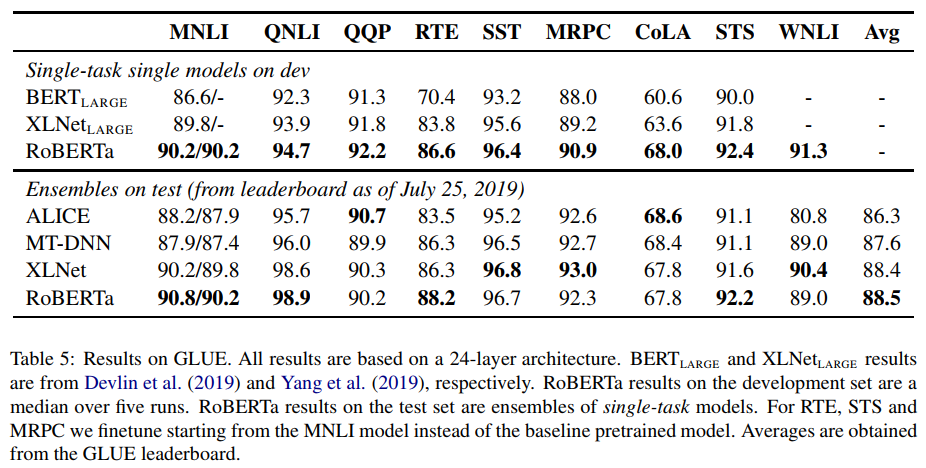
GLUE Results
SQuAD Results
BERT나 XLNet은 다른 QA 데이터셋을 추가적으로 사용하였지만, RoBERTa는 오직 스쿼드 셋만을 사용하였다고 한다. 또한 다른 lr scheduer등을 사용하지않고, 모든 레이어에 동일한 lr값을 사용했다고 한다. SQuAD v1.1은 devlin의 파인튜닝 과정을 그대로 사용하고, v2.0에 대해서는 추가적으로 답이 있는지 확인하는 classifier loss를 결합하여 사용하였다고 한다.
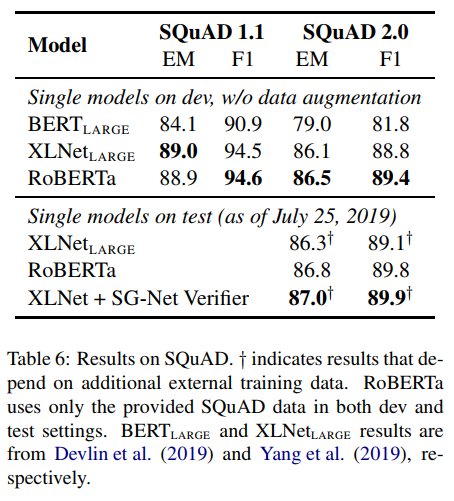
결과적으로 v1.1에 대해서는 XLNet large와 겨룰만한 성능을, v2.0에 대해서는 SOTA를 기록하였다.
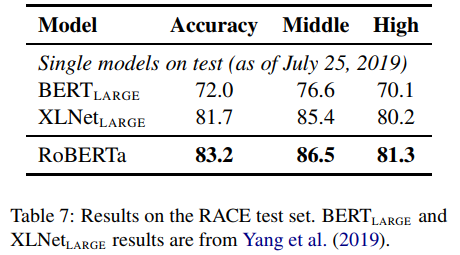
RACE Results
RACE는 문단, 질문, 4개의 후보정답군이 주어지면, 어떤 답이 맞는 답인지 찾는 문제이다. 이 테스크에 맞춰서 저자는 각 후보 정답을 문제와 문단과 함께 concat하고, 이를 패싱하여 나온 [CLS]토큰벡터를 FC layer에 통과시켜 나온 representation값으로 정답을 예측한다. qa pair의 길이는 128token으로, 문단까지 포함한 길이는 512로 제한하였다. 결과적으로 SOTA를 기록하였다.
○ Conclusion
Roberta는 BERT가 아직 과소적합되어있으며, 몇몇 학습파라미터, 학습방식을 변경함으로써 BERT가 좀 더 나은 성능을 낼 수 있음을 보여주었다. 이로써 이전의 연구에서 간과된 요소들의 중요성을 확인하고, 최근에 제안된 다른 모델과 겨루어도 충분히 경쟁력이 있을 수 있음을 보여주었다.
SpanBERT
이 방식으로 span selection과 연관있는 question answering이나, coreference resolution task 뿐만 아니라, GLUE와 같은 task에서 성능을 향상시킬 수 있음을 보인다.
많은 NLP task들이 두개 이상의 span 사이의 관계에 대한 추론을 포함한다. “Which NFL team won Super Bowl50?”과 같은 질문이 주어졌을 때, “Broncos”라는 단어를 알고 “Denver”를 유추하는것보다 “Denver Broncos”룰 유추하는 것이 훨씬 어렵다. SpanBERT는 BERT에 random continous span masking과 모델이 masking된 span 전체를 그 경계의 토큰으로부터 유추하는 SBO(Span Boundary Objectives)를 도입한다. SBO는 span-level의 정보를 boundary tokens에 저장하게 만든다. 또한 single segments를 pretraining하고 NSP를 제외하는 것이 성능에 좋은 영향을 줌을 보여준다.
○ Model
SpanBERT는 기본적으로 BERT의 구조를 따른다. 다만, span의 선택 방식이 다르고 NSP를 제거한 후 SBO를 선택하였다.
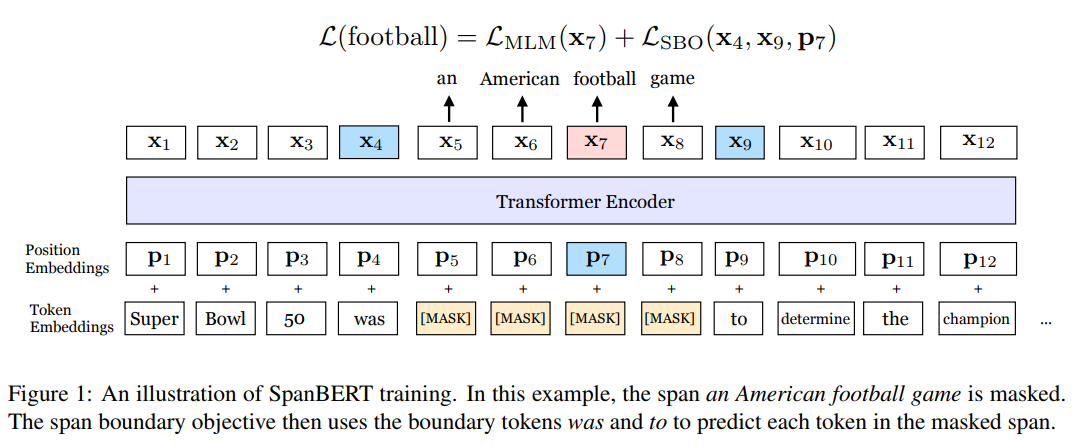
Span Masking
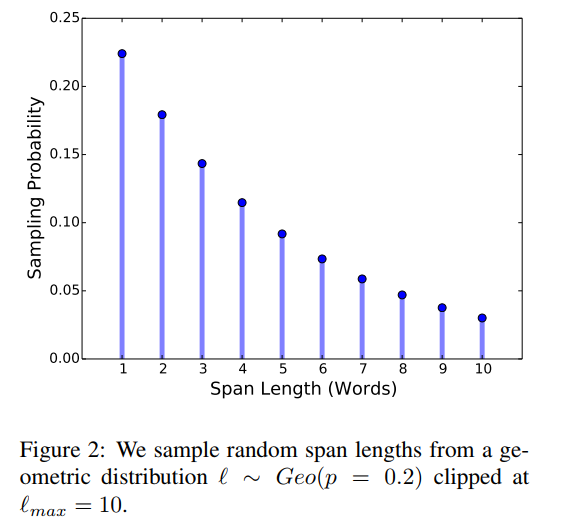
token sequence의 15%가 masking되어있도록 만드는데 이때, span의 길이를 geometric distribution($l∼Geo(p)$)에 의해 선택하고, 랜덤하게(uniformly) span의 시작위치를 선택한다. 저자는 $p=0.2$, $l_{max}=10$로 설정하여 $\overline{l}=3.8$이 되도록 하였다. 또한 span의 길이는 subword tokens이 아닌 complete word단위가 되도록 하였다. BERT의 경우 선택된 15%의 마스킹 토큰 중 80%는 [MASK]로 10%는 원단어로 10%는 랜덤한 토큰으로 대체하였는데, 저자는 이 때 각각의 toekn단위가 아닌 span레벨로 대체하였다.
Span Boundary Objective(SBO)
저자는 span의 끝에 최대한 많은 span 내부 컨텐트를 압축하기 위해, 경계의 토큰을 사용하여 마스킹된 스팬을 예측하는 SBO를 도입했다. 타겟 토큰의 positinoal embedding($p_i$)과 boundary token의 인코딩($x_{s-1}, x_{e+1}$)을 이용하여 $y_i$를 구하게 된다. 이를 구현할 때는 GeLU activation와 layer normalization을 결합한 2layer의 feed forward layer를 결합하여 사용한다.
\(y_i = f(x_{s-1}, x_{e+1}, p_i)\) \(h = LayerNorm(GeLU(W_1·[x_{s-1}; x_{e+1}; p_i]))\) \(f(·) = LayerNorm(GeLU(W_1·h))\)
최종적으로 span boundary loss와 masked lm loss가 함께 합해져 학습하게 된다.
Single-Sequence Training
BERT의 경우 sequence 두개를 뽑아 $(X_A, X_B)$ 모델이 NSP를 예측하도록한다. 그러나 이러한 셋팅이 오히려 더 안 좋은 결과를 보임이 관측되었다. 오히려 single sequence를 사용하고 NSP를 제외하는 것이 결과가 좋았는데 이에 대해 저자는 모델이 더 긴 길이의 context를 보는 것이 이득이고, NSP를 위해 다른 documnet에서 시퀀스를 뽑을 경우 우히려 노이즈가 추가될 수 있다고 해석하였다.
○ Experimental Setup
○ Results
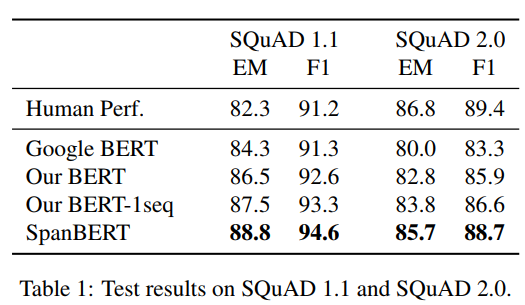
Question Answering task인 SQuAD뿐만 아니라 다른 MRQA 데이터셋들에서 일관적으로 향상된 성능을 보였준다.
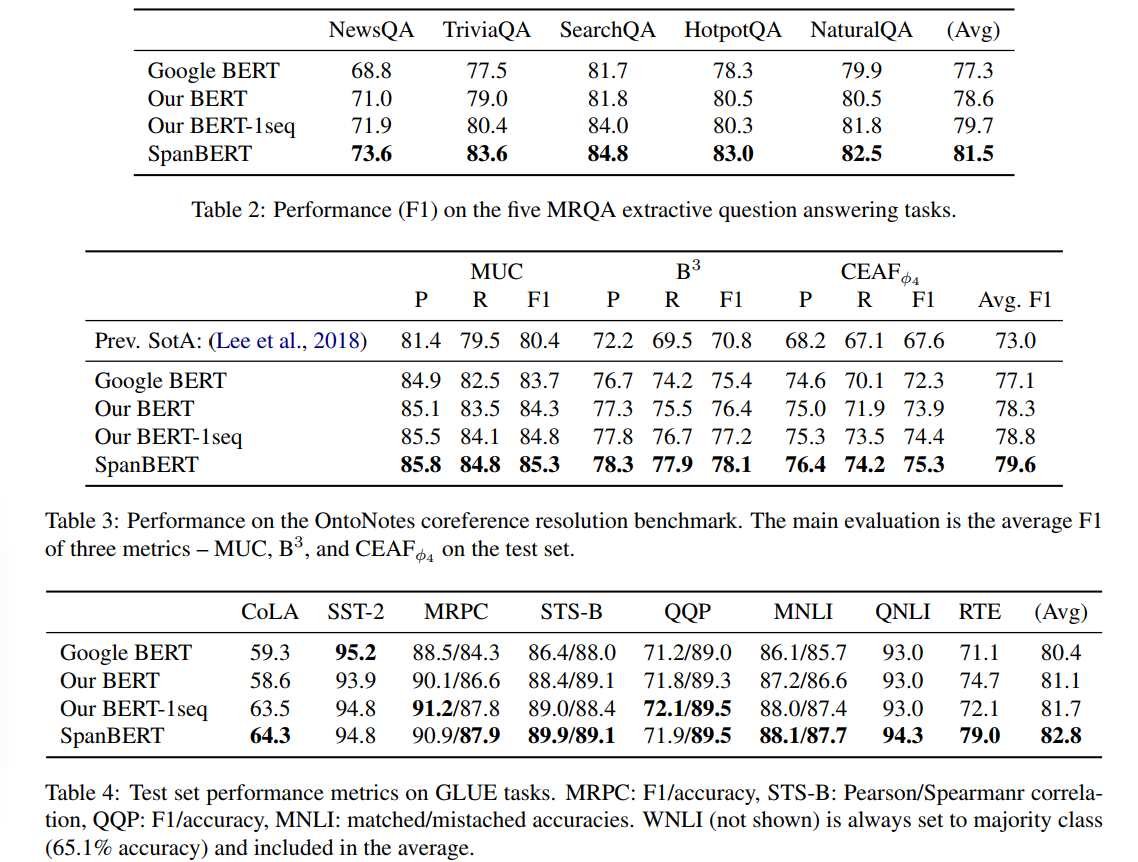
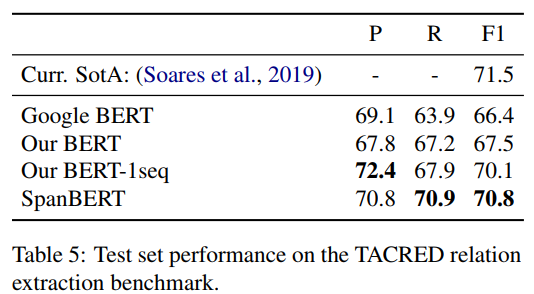
Coreference Resolution task에 대해서 79.6 F1 score를 얻어 SOTA를 획득하였다.(table3) Relation Extraction(table5)에서는 F1에서 sota를 recall에서 많은 향상을 기록했다. GLUE(table4) 데이터셋에 대해서도 실험이 진행되었는데, NSP를 제거한 것이 CoLA에서 상당항 향상을 나머지 테스크에서는 어느정도의 향상을 보였다. SpanBERT는 17가지의 baseline에 대해 기존 BERT와 성능을 비교하였고 이중 14가지 task에 대해서 성능향상을 보였다. 특히 extractive question answering task에서 큰 향상을 보여줬다. 결론적으로 downstream task에서 하나의 더 긴 sequence를 보고, NSP를 제거하는 것이 더 효과적임을 관찰할 수 있다. 이는 BERT의 비교실험과 반대의 결과이다. devlin의 구현에서 NSP ablation 실험을 할 때도 sequence 두 가 들어갈 것으로 예상되기에 더 긴 범위의 feature를 보는것이 중요함을 시사한다라고 볼 수 있다.
○ Ablation studies
이 섹션에서 저자는 masking scheme과 SBO(span boundary objective)가 어떤 영향을 주는 지 비교하였다.
Masking Schemes
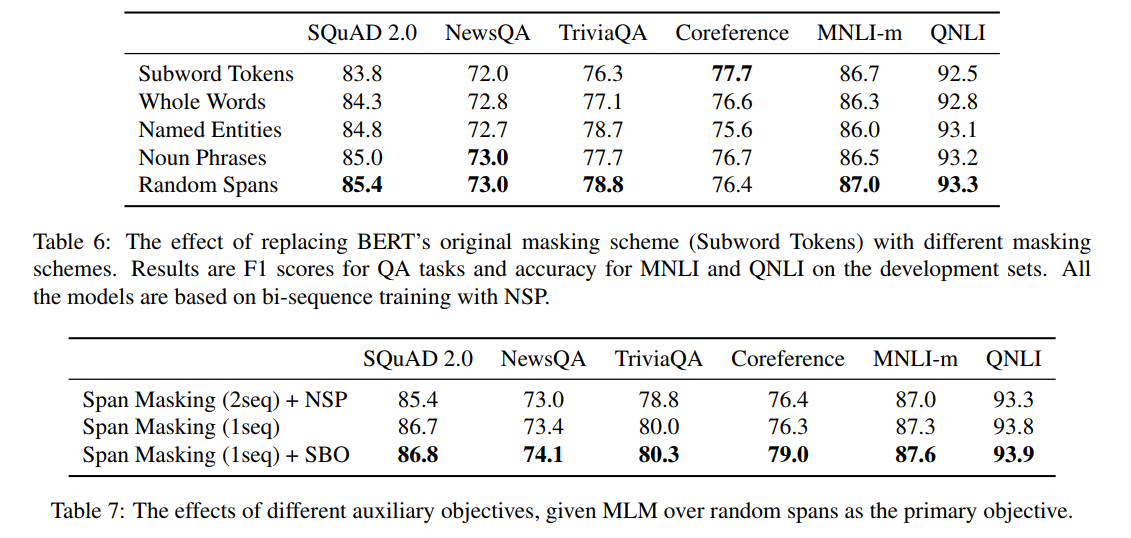
이전 연구(ERNIE)에서 언어학적인 정보를 가진 span masking으로 학습된 모델이 end-task에서 좋은 성능을 낼 수 있다는 것을 보여줬다. 저자는 이러한 언어학적 정보바탕의 span masking과 random span masking을 비교하였다.
- Subword Tokens : 오리지널 BERT방식으로 wordpiece token단위로 마스킹한다.
- Whole Words : word단위로 랜덤하게 마스킹한다. 마스킹된 subtokens의 수가 15%를 유지하도록 한다.
- Named Entities : 50%의 확률로 named entity를, 나머지 50%의 확률로 whole words를 랜덤하게 뽑아 마스킹한다. named entity는 spacy를 사용하여 뽑았다고 한다.
- Noun Phrases : 위와 유사하게 50%의 확률로 noun을 뽑고, spacy를 사용한다.
- Random Spans : geometric distribution을 따르는 random span masking으로 SpanBERT에서 사용하는 방법이다.
 {:.aligncenter}
{:.aligncenter}
위 표에서 확인할 수 있듯이 random span masking을 적용할때 대부분의 테스크에서 더 우수한 성능을 보였다. Coreference task에서 subword token단위 masking이 더 좋은 성능을 보였지만, 이는 SBO를 통해서 극복할 수 있는 수준임을 table7에서 확인할 수 있다.Auxiliary Objectives
NSP objective를 추가하는것이 single-sequence training과 비교해서 downstream task의 성능에 악영향을 끼칠 수 있음을 위 표에서 볼 수 있다. 반면 SBO는 부정적인 영향을 보이지 않았다.
○ Conclusion
저자는 BERT를 확장하여 span기반의 pretraining method를 제시하였다. 연속된 random span을 마스킹하고, masked span의 전체 컨텐트를 예측하는 span boundary representation을 학습하여 BERT 베이스의 tgask성능을 능가할 수 있음을 보여주었다.

Huiwon Yun
아무것도 하지않으면 아무일도 일어나지 않는다.