NLP Pretrained Model : BERT (1)
- 6 mins작년 11월, 구글에서 발표한 NLP Model인 BERT로 인해 AI/NLP 커뮤니티들이 시끌벅적했었다. 기존 NLP문제들은 각각의 task를 풀기 위한 구조를 설계하는 방식이었는데, Bert는 하나의 pretrained model에 기반하여 fine-tunning만으로 여러 task에서 SOTA를 기록함으로써 NLP의 판도를 완전 바꾸어 놓았다. 누군가는 지금까지 나왔던 nlp model 중 best라고 칭송할만큼, BERT는 연신 화제였다. 이 포스팅 시리즈에서는 BERT 를 우선 정리하고, BERT 이전의 language pretrained model이었던 GPT와 ELMo, ULMFiT 등에 대해 정리한다.
BERT : Pre-tarining of Deep Bidirectional Transformers for Language Understanding
Abstract
BERT는 Bidirectional Encoder Representations form Transformer의 약자이다. 그 이름 그대로 BERT는 transformer 의 인코더를 multi layer로 쌓은 구조를 취한다. (참고로 bert는 sesame street라는 프로그램의 캐릭터이기도 하다. 이전에 feature extranction방식인 nlp pretrained model인 ELMo(역시 같은 프로그램의 캐릭터이름)가 등장한 이후, sesame street의 캐릭터 이름들이 pretrained model 이름에 붙고 있다. 얼마전 MS에서 big bird라는 이름의 모델이 리더보드에 등장하기도 했다.) BERT는 모든 레이어에서 좌우 문맥을 모두 취하여, deep Bidirectional representation을 pre-train하도록 디자인 되었다. 이 pre-trained representation에 하나의 output alyer를 추가하여 fine-tunning하는 간단한 방식으로 QA, language inference등 다양한 task에서 state-of-the-art를 찍었다. (squad 1.0에선 human performance를 넘기도 하였다.) 또한 구글에서 github에 bert open source를 공개하기도 했다.(그러나 실제 페이퍼와 완전 동일한 모델은 아니다. 실제 구글에서는 텐서플로우로 작업하지 않았음을 언급하였고,(c++을 사용했다고 한다. 파라미터값들도 동일한지 확인되지않았다.)
1. Introduction
language model pre-training은 많은 nlp task에서 성능향상을 보여왔다. (semi supervied sequence learning, ELMo, ULMFiT, GPT 등) pre-trained language representation을 downstream task에 적용시키는 방법으로 크게 두가지가 있는데 하나는 feature-based 방식이고 다른 하나는 fine-tunning방식이다. ELMo가 전자의 방식을 사용하며, 기존 task-specific한 모델구조에 pre-trained representaition을 추가적인 feature로 사용한다. 후자인 fine-tunning방식은 GPT에서 사용되었는데, 최소한의 task-specific한 파라미터를 pretrained parameter에 더해 fine-tunning하는 방식이다. 논문저자는 기존 LM(language model)의 단방향 구조를 사용한것이 가장 주요한 한계포인트였음을 지적한다. 특히 openai의 GPT가 left-to-right구조로 모든 토큰이 이전 토큰만을 self-attention하기 때문에 양방향의 문맥을 종합하여야하는 SQuAD와 같은 QA task 에 치명적이었을것이다. 이에 BERT는 입력의 토큰을 랜덤하게 masking하여 이 masking된 단어를 예측하는 masked LM을 pre-trained model 의 objective로 사용할 것을 제안하였다.(1953 taylor의 Cloze task에 영감을 받았다.) 이로써 deep bidirectional transformer를 사용할 수 있게 되었다.
이 논문의 기여한 바를 정리하면 다음과 같다.
- language representation을 위한 pre-training 에서 양방향의 중요성을 보인다. Bert는 단방향이 GPT와 다르게 Masked LM을 사용하여 양방향으로 학습시켰다. ELMo가 left-to-right, right-to-left를 독립적으로 학습시킨 concatenation 구조인 것과도 비교된다.
- pre-trained representation은 task-specific한 구조의 필요성을 제거할 수 있음을 보였다.
- 11개의 NLP task에서 sota를 기록하였다.
2. Related work
Feature-based Approaches
nlp모델에서 pretrained word embedding을 사용하는 것은 필수불가결한 요소로 여겨져왔다. ELMo는 language model에서 context-sensitive feature를 추출하여 사용할 수 있음을 보였다. SQuAD를 비롯하여 sentiment analysis등 다양한 task에서 sota를 보였었다. (한떄 이런 task 리더보드에서 elmo를 덧붙인 모델들이 상위권을 이루었었다.)
Fine-tuning Approaches
최근 트렌드는 LM objective의 모델 구조를 pre-train한 후, 같은 모델을 supervied ownstream task에 맞게 fine-tunning하는 방식이다. (semi supervied sequence learning, GPT, ULMFiT 등) 이러한 모델의 장점은 scratch부터 학습되는 파라미터가 매우 적다는 것이다. GPT는 GLUE benchmark의 여러 sentence-level task에서 sota를 기록했었다.
Transfer Learning from Supervised Data
NLI, NMT, Vision task에서 supervised task에서 pretrain된 모델의 transfer를 하는 방식이 효과가 있음을 보여왔다.
3. BERT
Model Architecture
BERT는 multi-layer Bidirectional Transformer encoder 구조로 되어있다. 최근 transformer가 아주 흔하게 사용되고 bert도 동일한 구조를 사용하기 때문에 논문에서 transformer에 대한 자세한 언급은 생략한다. transformer의 구조에 대해 좀더 자세히 알고싶다면, transformer paper(attention is all you need)나 Annotated transformer(transformer에 대해 코드와 함께 좋은 가이드를 준다.)를 참고할 것. BERT는 parameter를 달리하여 BERT_base와 BERT_large로 구분된다. (BERT_base 모델은 GPT와 동일한 모델사이즈를 가져, 둘을 비교하기 쉽게 한다.) BERT의 transformer와 GPT의 transformer가 다른 점은 BERT쪽은 bidirecitional self-attention 을 취하지만, GPT의 것은 왼쪽 방향만으로 self-attention을 취한다는데 있다. 이 점 때문에 BERT에서는 자신들의 것을 transformer encoder라고 부르고 GPT의 것을 transformer decoder라고 부른다.
Input representaition
input은 token, segment, position embedding이 합쳐진 구조로 아래 그림과 같다. input은 single text sentence 거나 sentence pair이다.
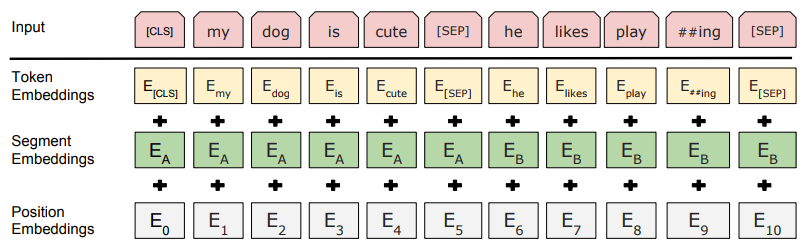
주요 특징으로 wordpiece embedding을 사용하였고, word piece는 ##으로 구분된다. (transformer와는 다르게) 학습되는 positional embedding을 사용한다. 각 sequence의 첫 토큰은 항상 CLS이다. 이 토큰의 final hidden state가 classification task에서 sequence representation을 종합하는데 사용된다. sentence를 구분하기 위해 [SEP]토큰과 segment embedding을 함께 사용한다.
Pretraining Task
ELMo나 GPT와 다르게 새로운 unsupervised prediction task로 BERT를 pretraining한다.
Task #1: Masked LM
기존의 Language Model은 multi-layered context에서 bidirectional할 경우 간접적으로 자신을 볼 수 있게 되기 때문에 (예측해야할 단어의 정보가 들어감) 얕게 left-to-right, right-to-left로 학습될 수 밖에 없었다. 따라서 BERT는 입력의 일부 token을 랜덤하게 마스킹 하고 그 토큰을 예측하는 방식으로 훈련시켜 deep bidirectional representation으로 학습할 수 있도록 하였다. 이를 masked LM으로 명명한다.(이미 이러한 task는 Cloze task로 언급되어왔다.) 실험에서, 전체 wordpiece의 15%를 랜덤하게 마스킹한다. 또한 auto encoder 와는 다르게 전체 input을 재구성하진 않고, 오직 masking된 word만을 예측한다. 그러나 이러한 접근방식에 문제점이 있는데, 바로 masking된 단어가 fine-tunning task에서 나타났을때, mismatch를 일으킬수 있다는 점이다. 이를 해결하기 위해 masking되기로 선택된 단어는 80%는 [MASK]토큰으로 대체되고, 10%는 random word로 대체되며, 나머지 10%로는 그대로 사용한다. (10% 그대로 사용함으로써 실제 word의 representation에 편향되게 한다.) random word로 대체되는 경우는 10%*15% 즉 1.5%의 확률로 일어남으로 전체적인 모델 성능에 영향을 끼치지 않을것이라고 판단했다고 한다.
- my dog is hairy라는 문장에서 hairy를 masking할 경우
- 80% of time : my dog is hairy → my dog is [MASK]
- 10% of time : my dog is hairy → my dog is apple
- 10% of time : my dog is hairy → my dog is hairy
Masked LM 의 두번째 단점은 수렴하기 위한 시간이 훨씬 더 걸린다는 것이다.
Task #2: Next Sentence prediction
QA나 NLI task처럼 문장간의 관계에 대한 이해가 필요한 경우, Language Modeling만으로 부족할 수 있다. 그래서 BERT는 Next Sentence Priection task를 pre-training에 추가시켰다. sentence A, B에 대하여 B가 A의 next sentence인지 아닌지에 대한 binary classification을 수행하는데, 50%의 확률로 B가 A의 next sentence가 되도록, 50%의 확률로 B가 A의 next sentence가 아니도록 입력 데이터를 만든다. 이 간단한 task가 얼마나 효과를 보이는지 Ablation study에서 확인한다.
[Example] Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] Label = NotNext
Pre-training Procedure
Pre-training코퍼스로 BookCorpus와 Enblish Wikipedia 를 사용한다. (book corpus의 경우 현재 사이트에서 제공하지 않아 따로 보존된 데이터를 찾거나 사이트에서 새로 크롤링해야한다.) documnet-level corpus를 사용하는 것이 중요하기 때문에 위키피디아에서 list나 table, header를 무시한다. 상세 사항은 다음과 같다.
- word piece tokenization후 15%비율로 LM masking
- sentence A와 B의 token 개수의 합을 512로 제한
- 100만 step == (33억 word corpus에 대해 40 epochs 학습)
- adam (bert release된 코드에서 adam decay 사용)
- L2 decay (0.01)
- dropout 0.1 all layer
- gelu activation
BERT_BASE는 4 Cloud TPUs, Bert_LARGE는 16 Cloud TPUs로 각각 4일씩 학습되었다고 한다. (TPU 당 각각 4TPU chip을 가지고 있고 1TPU chip이 16G memory를 가지니(Google reveals more details about its second-gen TPU AI chips 기사 참고) base모델을 학습하기 위해 사용한 memory만 해도 4*64G의 어마어마한 memory가 필요하다. 즉, 구글과 같은 환경을 따라하기도 힘들다.)
Fine-tuning Prodedure
sequence-level classification tasks에서 input sequence의 pooled representation으로 [CLS] tokens의 final hidden state를 취한다.(이 vector를 $C$라고 하자.) fine-tunning 과정에서 classification layer가 추가 되는데 이 layer를 통과하여 label probabilities $P=softmax(CW^T)$를 얻는다. span-level이나 token-level도 위 과정에서 살짝 수정된 정도로 진행된다. batch size, learning rate, training epoch 정도 외의 hypter-parameter는 pretraining때와 동일하다.
Comparision of BERT and OpenAI GPT
left-to right LM인 GPT와의 성능 비교를 위해 BERT의 학습 관련 많은 부분이 GPT와 비슷하게 선택되었다. 그럼에도 BERT 와 GPT 사이의 차이가 몇가지 존재한다..
- GPT는 BookCorpus 데이터로 학습하고, BERT는 BookCorpus 데이터에 wikipidia데이터를 추가로 사용한다.
- [SEP], [CLS] tokens은 GPT에서 fine-tunning task에 등장하지만, BERT는 pretraining 때, [SEP], [CLS], sentence embedding을 학습시킨다.
- GPT는 32K word를 1M step만큼 학습시키고, BERT는 128K word를 1M step 학습시킨다.
- BERT는 task-specific하게 leraning rate를 바꿔 사용한다.

Huiwon Yun
아무것도 하지않으면 아무일도 일어나지 않는다.