Multi-Task Learning
- 6 minsMT-DNN을 접하고 MTL(multi task learning)에 대한 관심이 생기게 되었다. 관련 자료를 찾던 중, 내가 좋아하는 연구자이자 블로거인 Sebastian Ruder가 멀티테스크러닝의 개요를 설명하는 페이퍼1 및 포스팅2을 작성한 것을 발견하게 되었다. 이 포스팅에서는 그 내용을 정리하고자 한다. 루더의 블로그에 최근의 흥미로운 MTL paper를 많이 소개하고 있으니 관심이 있다면 ruder.io에서 관련 포스팅을 찾아보는 것을 추천한다.
Overview of MTL in DNN
1. Introduction
보통 머신러닝 모델을 트레이닝할때 특정한 metric을 최적화하는데에 집중한다. 그래서 우리가 신경쓰는 metric보다 더 도움이 될수 있을지 모르는 정보를 무시하곤 한다. 관련있는 테스크들의 representation을 공유함으로써, 모델을 더 좋게 일반화할 수 있는데, 이러한 접근방식을 Multi-Task Learning이라고 한다.
MTL은 joint learning, learning to learn, learning with auxiliary tasks와 같은 이름으로도 언급된다. 즉, 하나보다 많은 loss fuction을 최적화하고자 할때, 이를 MTL한다고 할 수 있다.
2. Motivation
multi task learning을 하는 이유에 대해 다양한 방식으로 설명할 수 있다. 우선 생물학적인 관점에서, 새로운 것을 학습할 때 우리는 기존의 알고 있던 관련 정보를 사용한다. 교육학적인 관점에서 보면, 우리는 복잡한 테크닉을 배우기 전에 먼저 필요한 스킬들을 공부하곤 한다. 머신러닝의 관점에서, 우리는 MTL을 inductive transfer로 볼 수 있다. inductive transfer는 모델이 어떤가정을 다른것보다 선호하게하는 inductive bias를 줌으로써 모델의 성능향상을 돕는다. 즉, MTL에서 보조 테스크에서 제공받은 inductive bias가 모델이 하나 이상의 task를 설명할 수 있는 가정을 선호하도록 만들어 준다.
3. TWO MTL methods for deep learning
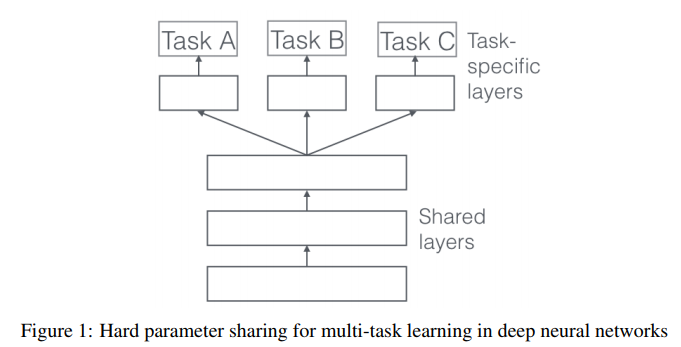
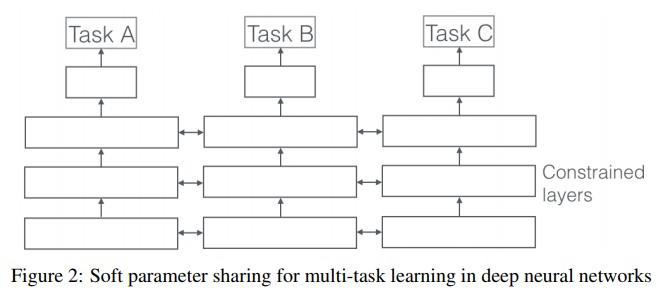 딥러닝에서 MTL은 전형적으로 hidden layer의 hard 또는 soft parameter sharing으로 행해진다. 전자(figure1)는 mtl에 대한 approach로 주로 이용되는데, task-specific output layer를 제외한 모든 테스크간의 은닉층을 공유하는것이다. hard parameter sharing은 overfitting을 줄여준다. 반면 후자(figure2)는 각가의 테스크가 각자 자신의 parameter를 가지는 모델을 가지며, 모델의 parameter간 거리를 regularize한다. 이러한 방식은 regularization technique에서 고안되어왔다.
딥러닝에서 MTL은 전형적으로 hidden layer의 hard 또는 soft parameter sharing으로 행해진다. 전자(figure1)는 mtl에 대한 approach로 주로 이용되는데, task-specific output layer를 제외한 모든 테스크간의 은닉층을 공유하는것이다. hard parameter sharing은 overfitting을 줄여준다. 반면 후자(figure2)는 각가의 테스크가 각자 자신의 parameter를 가지는 모델을 가지며, 모델의 parameter간 거리를 regularize한다. 이러한 방식은 regularization technique에서 고안되어왔다.
4. Why does MTL work?
MTL을 좀 더 잘 이해하기 위해서 MTL에 내재된 메커니즘을 확인할 필요성이 있다. 아래 대부분의 내용은 caruana에 의해 처음 제안되었다.
Implicit data augmetation
MTL은 데이터 샘플 사이즈를 키우는 효과가 있다. 어떤 테스크에 대한 representation을 잘 학습하기 위해서는 데이터 의존적인 노이즈를 무시하고, 일반화할 수 있어야 한다. 다른 테스크는 다른 노이드패턴을 가지고 있고, 모델이 여러 테스크를 동시에 학습하면 좀더 일반적인 표현을 학습할 수 있다.
Attention focusing
테스크가 noisy하거나 데이터가 제한되었거나 고차원의 문제라면 모델은 어떤 feature가 관련이 있고 어떤 feature가 관련이 없는지 구분하기 어려워한다. MTL은 다른테스크들에도 중요한 feature에 attention하게 함으로써 feature의 관련성/무관성을 구분할 추가적인 증거를 제시한다.
Eavesdropping
어떤 feature는 어떤 테스크에선 학습하기 쉽지만 다른 테스크에선 그렇지 않을 수 있다. MTL을 통해, 모델은 eavesdropping(엿듣기)가 가능해지는데 이것이 바로 모델의 학습을 도울 힌트가 될 수 있다.
Representation bias
mtl은 다른 테스크 또한 선호하는 representation을 선호하도록 bias를 준다.
Regularization
mtl은 inductive bias를 주는 regularizer처럼 행동하여 오버피팅을 줄여준다.
6. Recent work on MTL for deep learning
최근 많은 딥러닝 방식에서 mlt이 사용되었지만 대부분 hard 또는 soft parameter sharing하는 방식으로 한정되어있었다. 그 외 몇몇 다른 접근방식을 소개한다.
Deep relationship network
deep relationship network는 fc layer에 matrix prior를 위치시켜 모델이 테스크간의 관계를 학습할 수 있도록 하였다. (이전에 본 베이지안 모델과 비슷한 접근방식) 그러나 이러한 방식은 이미 정의된 구조에 의존적이기 때문에 computer vision 문제와 같이 잘 연구된 문제에 적합하고 새로운 테스크에 대해선 증명이 필요하다.
Fully-Adaptive Feature Sharing
학습하는동안 다이나믹하게 네트워크를 넓히는 방식이 제안되었다. 그러나 이 그리디한 방법은 글로벌하게 최적화함을 증명하기 어렵고, 테스크간의 복잡한 상호작용을 모델이배우게 하기 어렵다.
Cross-stitch network
soft parameter sharing에 cross-stitch unit을 적용하여 모델이 다른 테스크의 knowledge를 활용할 방법을 결정하도록 하였다.
Low supervision
nlp에서는 테스크의 계층성을 찾는데 집중한 연구들이 나왔다. lower layer에서 auxiliary task로 low-level task(pos, ner)등을 사용하였다.
A Joint Many-Task Model
다수의 nlp테스크로 구성된계층적인 구조를 정의하였다.
Weighting losses with uncertainty
sharing 구조를 학습하는 대신에, 각 테스크의 불확실성을 고려하는 orthogonal 방식을 취하였다. 각 테스크의 상대적인 weight를 조정하였다.
Tensor factorisation for MTL
model parameter를 공유하는 부분과 task-specific한 부분으로 분리하는 tensor factorisation을 사용하여 matrix factorisation을 일반화하였다.
sluice network
어떤 레이어와 서브스페이스가 공유되어야하는지 어떤 레이어가 input seq의 best representation을 학습하게 하는지를 학습하게 한다.
what should i share in my model?
대부분의 방식은 같은 분포를 가지는 테스크에 초점을 가지는 시나리오를 사용한다. 그러나 모델을 더 강력하게 만들기 위해서 관련없거나 느슨하게 관련된 테스크가 필요할 수 있다. 하드 파라미터 쉐어링은 20년이 지난 지금도 일반적으로 사용되고 있다. 최근 연구는 이를 넘어서 무엇을 공유할지 학습하는 방향을 보고 있다. 같은 파라미터 스케이스 안에 우리 모델을 제한하는것보다 테스크들이 어떻게 상호작용할지에 대한 논의가 더 필요하다.
7. Auxiliary tasks
대부분의 경우, 테스크 하나의 성능만을 고려한다. 이 섹션에서는 MTL의 이점을 얻기위해 적합한 보조테스크를 찾는 방법에 대해 살펴볼 것이다.
Related task
고전적인 방법은 관련 테스크를 사용하는 것이다. 예를 들어 방향을 예측하기 위해 도로의 특성을 예측하거나, facial landmark detection을 위해 머리포즈를 감지하고, 얼굴요소를 추론하는 것이 보조 테스크로 관련 테스크를 이용한 것이다.
Adversarial
우리가 원하는 것과 반대되는 테스크를 이용할 수도있다. 즉 adversarial loss를 사용하는 것이다. 이러한 설정은 domain adaptation에서 성공적이었음을 보였다. adversarial task의 gradient를 리버싱하면 adversarial loss가 최대화되고 이것이 main task에 이득이 되는 방향이다. 이 방법이 모델이 도메인간 구별하기 어려운 representation을 학습하도록 도와준다.
Hints
원래의 테스크에서 배우기 힘든 feature를 학습하기 위해 힌트를 사용할 수 있다. 감정분석 테스크에서 문장이 긍정 또는 부정의 단어를 포함하는지를 예측하거나, name error detection을 위해, 이름이 문장에 존재하는지 예측해 볼 수 있다.
focusing attention
모델이 무시하는 부분에 attention하기 위해 사용될 수 있다. 예를 들어 facial landmark 위치를 예측하는 테스크에서 얻은 지식을 facial recognition 테스크에서 사용할 수 있다.
Quantization smoothing
많은 task에서의 목적함수는 양자역학이 적용되었다. 예를 들어 연속 스케일이 좀 더 타당하며, label은 이산집합에 존재하는 경우가 그렇다. 좀 더 덜 양자역학이 적용된 보조테스크의 경우 목적함수가 좀 더 매끈하여, 학습에 도움이 될 수 있다.
Predicting inputs
input이 아닌 output을 feature로 사용할 수 있다.
Using the future to predict the present
어떤 feature의 경우엔 예측이 끝난 후 사용가능할 수 있다. 이러한 데이터는 런타임 중에는 input으로 사용할 수 없을 수 있으나, 학습중에는 추가적인 지식을 주기위해 보조 테스크로 사용할 수 있다.
Representation learning
모델이 transferable representation을 학습할 수 있도록 테스크를 적용함으로써 명시적으로 모델링이 가능하다. LM objective가 이러한 역할을위해 적용되었다. 비슷한 방식으로 오토인코더가 보조 테스크로 사용될 수 있다.
What auxiliary tasks are helpful?
보조 테스크를 찾는 것은 보조테스크가 어떤 방식으로든 메인 테스크와 연관이 있어서 메인테스크를 예측하는데 도움이 될 것이라는 가정에 기반한다. 그러나, 언제 테스크가 유사하거나 관련이 있다고 정의할 수 있는지에 대한 토론이 여전히 필요하다. caruana는 테스크들이 같은 feature를 가질 경우 유사하다고 정의하였고, baxter는 이론적으로 공통의 optimal hypothesis class를 공유해야 한다고 주장했다. ben-david and schuller는 테스크가 고정된 확률분포해서 생성될때, 두 테스크가 f-related하다고 정의하였다.
8. conclusion
20년 동안 MTL은 hard parameter sharing 방식이 만연했다. 하지만 최근에는 무엇을. 공유할지에 대한 연구가 유망해졌다. 현재 테스크의 유사성과 관계, 계층, mtl에서의 이점에 대한 이해는 아직도 제한적이므로 이에 대한 연구가 계속 필요하다.
Reference

Huiwon Yun
아무것도 하지않으면 아무일도 일어나지 않는다.